ちょっと昔のInnovative Tech(AI+)
そのAIモデルの良い精度結果、たまたま“良い乱数”を引いただけかも? ランダムシードの影響を調査、21年の研究結果
ちょっと昔のInnovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。通常は新規性の高いAI分野の科学論文を解説しているが、ここでは番外編として“ちょっと昔”に発表された個性的な科学論文を取り上げる。
X: @shiropen2
フランスの研究者であるデビット・ピカールさんが2021年に発表した論文「Torch.manual_seed(3407)is all you need: On the influence of random seeds in deep learning architectures for computer vision」は、深層学習アーキテクチャにおいてランダムシード(乱数生成器の初期値)の選択が精度に大きな影響を与えるかを検証した研究報告である。
 ランダムシードの選択はAIモデルの精度にどのくらい影響を与えるか?
ランダムシードの選択はAIモデルの精度にどのくらい影響を与えるか?
この研究では、CIFAR-10データセット(6万枚の画像データ)に対して最大1万の異なる乱数シードをResNet9で試し、さらにImageNetデータセットでは事前学習モデル3種を用いて少数のシードを検証した。今回はコンピュータビジョン分野の深層学習モデルに焦点を置く。
結果として、良い精度がでる当たりのシード(または悪いシード)が存在することが分かった。またCIFAR 10では同じモデルでも最大1.82%(89.01%~90.83%)の精度差が、ImageNetでも約0.5%の精度差を確認できた。コンピュータビジョンの分野ではこの程度の精度差が“有意な差”として論文掲載の決め手になることがある。
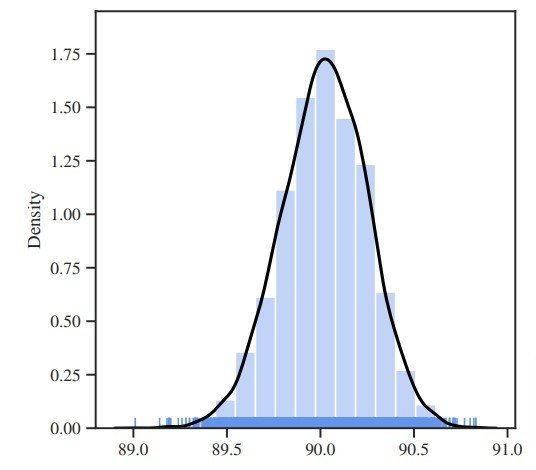 CIFAR-10データセットにおけるResNet9の104回の実行での最終検証精度の分布
CIFAR-10データセットにおけるResNet9の104回の実行での最終検証精度の分布
 CIFAR-10での精度結果
CIFAR-10での精度結果
 ImageNetでのモデル3種の精度結果
ImageNetでのモデル3種の精度結果
つまり、モデル自体や訓練方法を変えなくても、単にランダムシードが異なるだけで論文に採択されるほどの精度差が生じる可能性がある。これは、研究者が試行錯誤の過程で無意識のうちに“良いシード”を選んでいる可能性を示唆している。
この問題を解決するためには、より多くのシードでテストを行い、平均値、標準偏差、最小値、最大値などの統計情報を報告することが重要だと主張している。これにより、単一の実験結果に依存せず、モデルの真の性能をより正確に評価できるようになる。
Source and Image Credits: Picard, David. “Torch. manual_seed(3407)is all you need: On the influence of random seeds in deep learning architectures for computer vision.” arXiv preprint arXiv:2109.08203(2021).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
千代田区、Copilot全庁導入で月2000時間削減 10カ月でAIを根付かせた定着の仕掛け
-
2
AI・半導体企業トップが語る“稼ぎ頭” キオクシア、フジクラ、東京エレデバの見解まとめ【無料PDF】
-
3
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
4
Claude、一部チャットがGoogle検索で“丸見え”に 過去には「ChatGPT」でも 漏えいの原因は?
-
5
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
6
地震、台風、有事の寸断――日本のサプライチェーン危機管理を変えるとき
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
-
9
マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
-
10
「Claudeより4割安い」 M365のExcel/メール操作を丸投げる「Copilot Cowork」“従量課金”の落とし穴
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR