Anthropic、「Claude Opus 4.5」リリース コーディング能力や会話継続能力が向上
米Anthropicは11月25日(現地時間)、フラグシップAIモデルの最新版「Claude Opus 4.5」をリリースしたと発表した。「Opus」はClaudeの最大モデルだ。同社は9月に中型モデル「Sonnet」の、10月に最小モデル「Haiku」の4.5をリリース済みだ。

AnthropicはClaude Opus 4.5を、コーディング、エージェント、コンピュータの使用で世界最高のモデルで、同社がこれまでにリリースした中で最も高度なモデルと位置づけている。これまで数日かかっていた開発プロジェクトを数時間で完了させるコーディング能力や、曖昧な要求を処理し、複雑なマルチシステムバグの修正を自力で特定する能力を備えるという。
また、規制当局への提出書類や市場レポートを関連付ける金融分析、ログや脅威インテリジェンスを相関させるサイバーセキュリティのワークフローにも役立つとしている。
エージェント機能の強化として、プログラムによるツール呼び出しや、コンテキストウィンドウを圧迫せずに何百ものツールを動的に検索できるツール検索機能が開発者向けに導入された。従来モデルよりも少ないトークンでより良い結果を達成できるという効率性の向上も特徴の1つだ。
一般ユーザー向けアプリの改善点として、長いチャットが中断されることなく継続できるようになった。前モデルでは、チャットが非常に長くなると、一度に処理できる情報量の限界に達し、会話の内容を忘れ始めたり、一貫性が保てなくなったりする問題が発生していた。この問題を解決するために、必要に応じて以前の会話の内容を自動的に要約し、その要点を記憶に残す自動要約機能を組み込んだ。これにより、会話の重要な部分が常に最新の状態に保たれるため、「事実上、際限なくチャットを続けられるようになった」という。
また、「Claude Code」がデスクトップアプリでも利用可能になり、バグ修正やリサーチなどのタスクを複数のローカルおよびリモートセッションで並行して実行できるようになった。
安全性については、Anthropicがリリースした中で最も堅牢にアラインメントされたモデルだとしている。悪意のある攻撃に対する訓練や、プロンプトインジェクション攻撃に対するロバスト性が大幅に向上したため、業界の他のフロンティアモデルと比較してだましにくいとしている。
ベンチマーク結果としては、SWE-bench Verifiedで80.9%、Terminal-bench 2.0で59.3%を達成し、競合モデルを上回った。また、ARC-AGI-2 Verifiedでは37.6%、OSWorldでは66.3%を記録した。
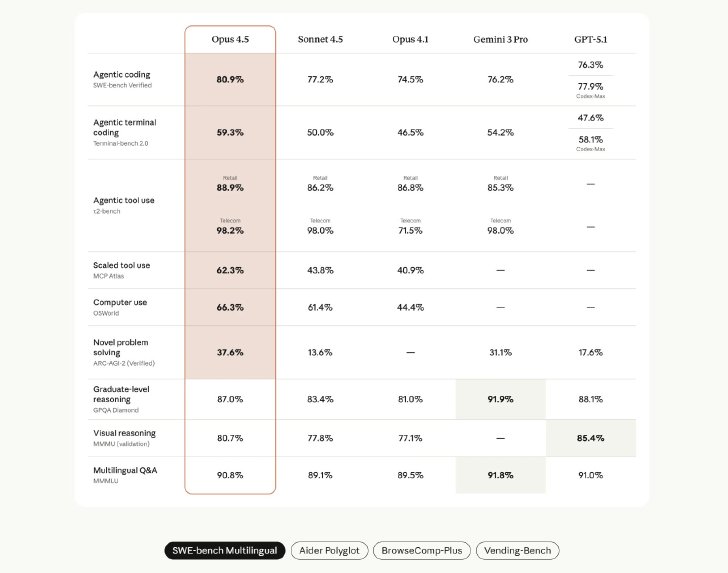 SWE-benchの結果比較(画像:Anthropic)
SWE-benchの結果比較(画像:Anthropic)
新モデルは、Anthropicのアプリ、API、主要な企業向けクラウドサービス(Google Cloud、AWS、Microsoft)で利用可能だ。Google CloudのVertex AIで一般提供されるほか、MicrosoftのFoundry、GitHub Copilotの有料プラン、Microsoft Copilot Studio、AWSのAmazon Bedrockでパブリックプレビューとして提供が開始された。Microsoftでの価格は、100万トークン当たり入力が5ドル、出力は25ドルだ。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
2
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
3
リコーが多能工ヒューマノイドを披露、工場ではPoCから導入に向けた実証段階へ
-
4
解剖・孫正義氏の「ガチョウ論」 「ソフトバンクG株価が低過ぎ」主張を信じてよいのか
-
5
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
6
カインズが画像AIで売上UP模索、店頭でのインテリア“試着”をテスト 立ちはだかる「正確性と効率」の壁
-
7
AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
-
8
AIは設計者を置き換えるのか Autodesk幹部に聞くCADと設計データの未来
-
9
ローカルLLMは本当に手元で動くのか? ハードウェアとモデルの現実的な選び方【2026年春】
-
10
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR