Innovative Tech(AI+)
“あいまい”検索システム「SoftMatcha 2」 東大や京大、Sakana AIなどが開発 巨大化するAI学習データを高速検索
Innovative Tech(AI+):

2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。X: @shiropen2
東京大学や京都大学、Sakana AIなどに所属する研究者らが発表した論文「SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora」は、巨大なテキストデータの中から、意味が似ている文を高速で探し出すアルゴリズムを開発した研究報告だ。
Webブラウザ上ですぐに試せるデモサイトも用意しており、入力した検索文の類似内容も類似度と用例件数とともにランキング形式で複数出力してくれる。
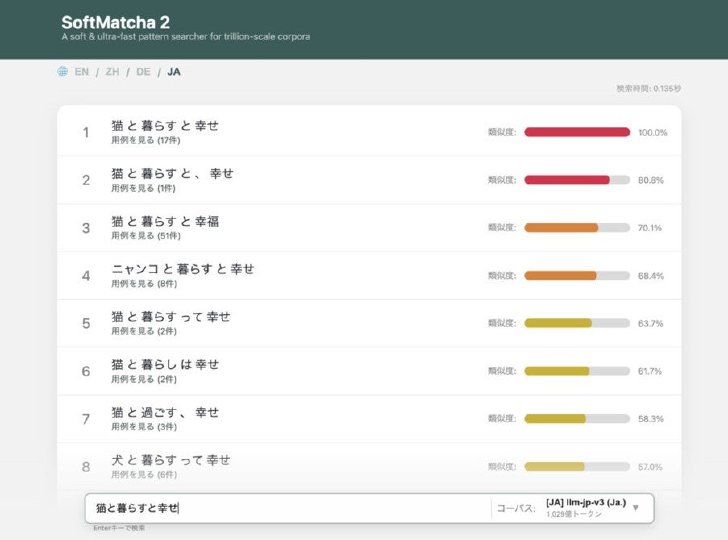 SoftMatcha 2のデモサイト 「猫と暮らすと幸せ」と言う検索文をした出力結果
SoftMatcha 2のデモサイト 「猫と暮らすと幸せ」と言う検索文をした出力結果
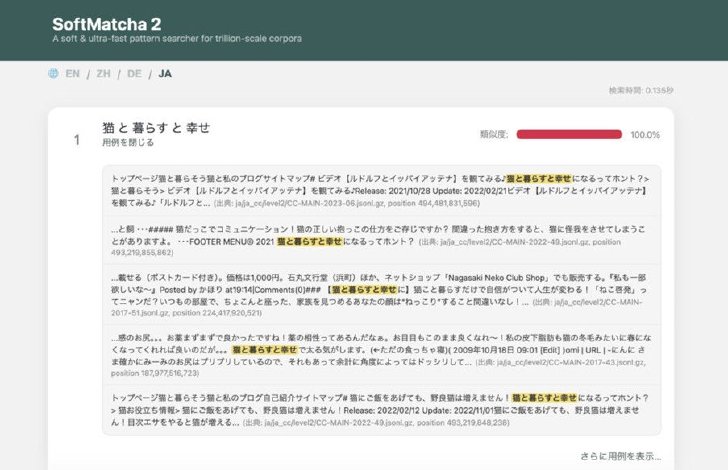 1位に出力された完全一致の「猫と暮らすと幸せ」の用例を開いた時の様子 「猫と暮らすと幸せ」という文言がコーパスのどこに使われていたかを表示している
1位に出力された完全一致の「猫と暮らすと幸せ」の用例を開いた時の様子 「猫と暮らすと幸せ」という文言がコーパスのどこに使われていたかを表示している
大規模言語モデル(LLM)の驚異的な進化の裏には、数兆トークンという途方もない規模のテキストコーパスが存在している。しかし、学習データが巨大化するにつれ、その中から特定のテキストやそれに類似する表現を素早く検索することは極めて困難になっている。
LLMの予期せぬ挙動の原因を探ったり、評価用テストデータが学習データに誤って混入していないかを確認したりするためには、単なる完全一致ではなく、類似する表現(意味的な近さ)を許容する、あいまいな検索ツールが不可欠だ。
従来のシステムにおいて、同義語への置き換えや単語の挿入・削除といった類似する表現を許容する検索を行おうとすると、検索候補となる文字列のパターンが指数関数的に爆発してしまい、現実的な時間で処理することができなかった。
研究チームが開発した「SoftMatcha 2」は、この計算量の爆発を防ぎつつ高速化を実現するために、主に2つのアプローチを採用。1つ目は、データの読み込み方の工夫だ。コンピュータの動きが遅くなる原因であるデータ保管庫(ディスク)からの読み出しを極限まで減らすアプローチを採用した。これにより、従来の最高峰ツール「infini-gram」の約33倍という速度を出した。
2つ目は、無駄な検索を省く。実際にコーパスに出現し得ない無駄な検索候補を動的に枝刈りする技術を採用した。これにより、検索文が長くなっても探索空間が爆発するのを防ぐことに成功している。
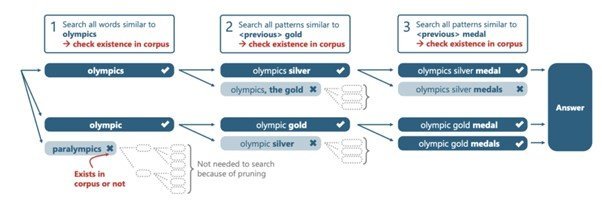 各ステップで類似単語を展開しつつ、コーパスに存在しないパターンを枝刈りすることで検索候補の爆発を抑える仕組み
各ステップで類似単語を展開しつつ、コーパスに存在しないパターンを枝刈りすることで検索候補の爆発を抑える仕組み
実際の性能評価において、SoftMatcha 2は1.4兆トークンを誇る巨大な英語コーパス「FineWeb-Edu」に対する柔軟な検索を、検索リクエストの95%が遅延278ミリ秒という実用的な速度で完了させた。また英語だけでなく、1690億トークンの日本語コーパスや383億トークンの中国語コーパスなど、多様な言語に対しても400ミリ秒未満での柔軟な検索に成功している。
この技術の最も強力な応用例の一つが、AIの性能評価を根本から脅かすベンチマーク汚染の検出だ。評価用データが学習データに漏えいしている場合、カンニングとなり正確なモデル評価が行えない。
従来では、評価用データの問題構造は同じで数字だけが書き換えられている場合や、少しだけ言い回しが違うだけの問題が学習データに混ざっていても見逃してしまっていた。しかしSoftMatcha 2を用いた実験では、完全一致検索だけではすり抜けてしまうカンニングデータの混入を高精度に炙り出すことができると実証された。
Source and Image Credits: Yoneda, Masataka, et al. “SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora.” arXiv preprint arXiv:2602.10908(2026).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」サブスクに統合 Max・Team Premiumプラン対象
-
2
Hugging FaceにAI主導のサイバー攻撃 防御もAIで対抗するも、商用モデルは解析拒否で「GLM」採用
-
3
Google、「NotebookLM」を「Gemini Notebook」に改称 Geminiエコシステムへの統合を強化
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
「AIと壁打ちはもう古い」 業務タスクを任せる「Claude Cowork」の落とし穴
-
6
「AIエージェントの約半数が"戦力外"になる」 なぜ企業は使いこなせない?
-
7
強気値上げで自爆か ClaudeやGeminiに押され「M365 Copilot」は一人負け?:888th Lap
-
8
Anthropicと組んだNEC それでも森田社長が「4つの主権」にこだわる真意
-
9
コードなしでもベイズ統計ができる無料の神ツール「JASP」 ~ マウス操作だけでここまでできる
-
10
日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR