Innovative Tech(AI+)
AIの“長期的なコードの保守能力”はどれほどか? 新たな評価テスト「SWE-CI」 中国チームが提案
Innovative Tech(AI+):

2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。X: @shiropen2
中国の中山大学とアリババグループに所属する研究者らが発表した論文「SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration」は、AIが長期的にコードの品質を維持できるかを評価するベンチマークを提案した研究報告だ。
AIにコードを書かせる技術はここ数年で急速に進歩した。GitHubに投稿されたバグ報告を読み取って自動で修正パッチを生成するといったタスクでは、人間のエンジニアに迫る性能を示すモデルも登場している。
しかし現実のソフトウェア開発を考えると、この評価だけでは不十分といえる。実際の開発現場では、ソフトウェアは一度完成したら終わりではなく、何カ月も何年もかけて機能追加やバグ修正を繰り返しながら育てていくものだからだ。
ソフトウェアの全コストのうち60~80%は完成後の保守に費やされるとされている。つまり、正しいコードを1回書く力とコードを長期間にわたって正しく保ち続ける力は全く別の能力なのだ。
こうした長期的なコードの保守能力を測るため、研究チームは「SWE-CI」という新しい評価テストを開発した。このテストでは、現実のソフトウェア開発で起きた平均233日間、71回の連続したコード更新をAIに試させる。
具体的には、実在するリポジトリから、ある時点のコードと約8カ月後のコードのペアを100組用意し、AIに何十回もコードを改善させながら良い状態を目指させる。設計役のAIが次に何を直すべきかを判断し、実装役のAIがそれに従ってコードを書くという分業体制で、現実の開発サイクルを模している。
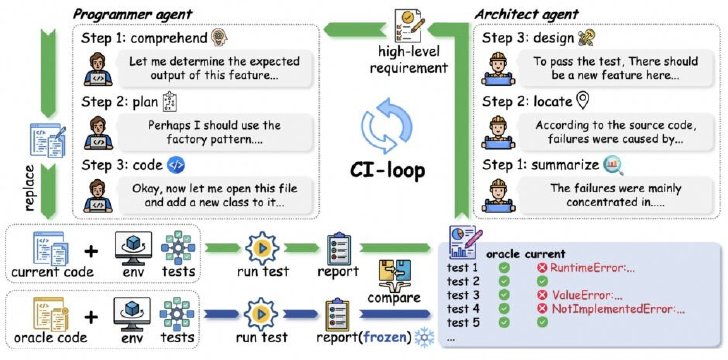 SWE-CIの仕組み 設計役がテスト失敗から要件を作成し、プログラマーが実装する反復ループで、長期的なコード保守能力を評価
SWE-CIの仕組み 設計役がテスト失敗から要件を作成し、プログラマーが実装する反復ループで、長期的なコード保守能力を評価
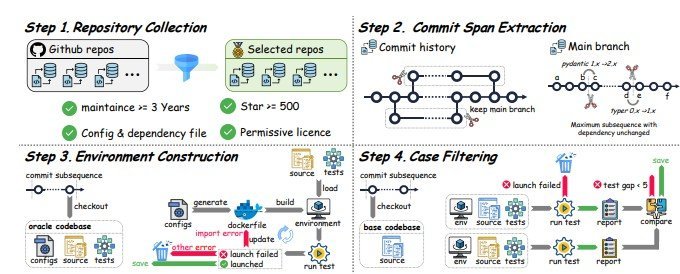 実際のGitHubリポジトリから条件を満たすものを選び、テスト環境を自動構築して最終的に100件の評価タスクを厳選するプロセス
実際のGitHubリポジトリから条件を満たすものを選び、テスト環境を自動構築して最終的に100件の評価タスクを厳選するプロセス
評価指標は後半の反復ほど重みが大きくなる設計で、序盤に急いでテストを通しても後半で行き詰まればスコアが下がる。目先のテストを通すためだけのツギハギだらけのコードを書くと、後々の変更が雪だるま式に難しくなり、最終的にAI自身がお手上げ状態になってしまう。つまり、その場しのぎをするAIが低く評価され、将来を見据えたコードを書くAIが高く評価される。
18モデルを試した結果、最も目立った発見はリグレッションの多さだ。リグレッションとは、ある箇所を直したせいで別の箇所が壊れる現象のこと。全工程を通じて一度も壊さなかった割合は大半のモデルで25%未満で、50%を超えたのはClaude Opusだけだった。一発の修正はうまくても、長く直し続けるとなるとAIはまだかなり危ういということを、このベンチマークは浮き彫りにしている。
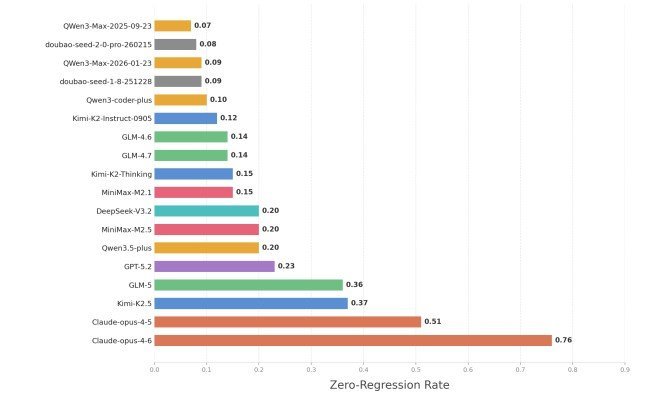 コード変更時に既存機能を一度も壊さなかった割合を示し、50%を超えたのはClaude Opus 4.5(51%)と4.6(76%)のみ
コード変更時に既存機能を一度も壊さなかった割合を示し、50%を超えたのはClaude Opus 4.5(51%)と4.6(76%)のみ
Source and Image Credits: Chen, Jialong, et al. “SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration.” arXiv preprint arXiv:2603.03823(2026).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
2
【役に立つの?】「Google公式」の初心者向けAI講座、受けてみたら想像以上にすごかった
-
3
Flashの再来? Figmaの新機能「Figma Motion」に懐かしいとの声 アニメーション生成するAI機能も
-
4
味の素、“万能DX人材”増員へ 育成のきっかけは新規プロジェクトの苦い経験
-
5
リコーが多能工ヒューマノイドを披露、工場ではPoCから導入に向けた実証段階へ
-
6
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
7
ClaudeをSlackチャンネルに召喚、“チームの一員”として直接指示 新機能「Claude Tag」登場
-
8
【解説】キオクシアなぜ急成長? 半導体メモリって何? AIブームを見通すための基礎知識
-
9
富士通と日本IBMの協業、ついに始動 COBOL刷新における「役割分担」は?
-
10
男性に美人局容疑で3人逮捕 ChatGPTの示談相場示し脅迫か 警視庁
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR