Google、複雑な会話型クエリでも意図をくんで答えるBERT採用検索を英語で開始
米Googleは10月25日(現地時間)、Google検索で自然言語処理「BERT」を採用し、検索結果に「過去5年間で最も大きな躍進」をもたらしたと発表した。まずは米国での英語による検索に適用し、提供地域や言語を拡大していく計画だ。
BERT(Bidirectional Encoder Representations from Transformers)は、Googleが昨年11月に発表した自然言語処理(NLP)のための言語処理モデル。おおまかに言うと、いくつかのキーワードを抜いた文を学習データセットにして機械語アルゴリズムを訓練し、アルゴリズムによる文脈の理解力を上げるというもの。
例えば長い会話型クエリや、「for」や「to」などの助詞に重要な意味があるクエリの場合、従来の検索では意図した結果を得られない場合が多かったが、BERT採用検索は文脈を理解した結果を表示するという。
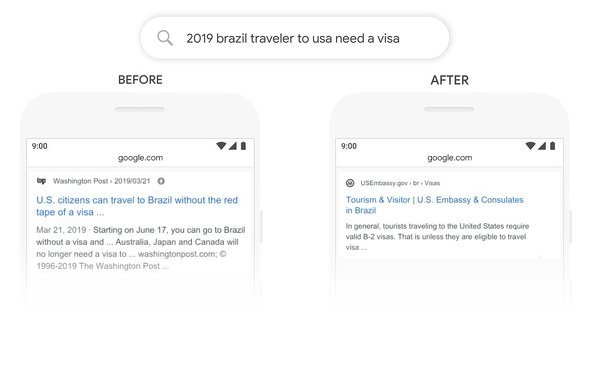
Googleは具体的な成果の例を幾つか紹介している。例えば、「2019 brazil traveler to usa need a visa(2019年にブラジルから米国への旅行者はビザが必要か?)」というクエリの場合、従来は助詞の「to」の重要性を理解せず、米国からブラジルへの旅行者に関する結果をトップに表示していたが、BERT版ではブラジルから米国への入国についての情報がトップに表示される。
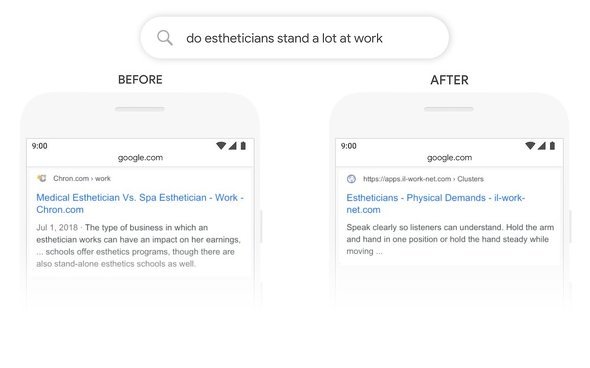
「do estheticians stand a lot at work(エステティシャンは仕事中長く立っているか)」というクエリでは、従来は「stand」を「stand-alone」とマッチングさせてしまい、クエリで知りたい物理的な立ち仕事かどうかという疑問とは直接関係ない結果を表示していたが、BERTであればエステティシャンの身体的負荷についての説明がトップに表示される。
BERTで構築するモデルの一部は非常に複雑で従来のハードウェアはその負荷に耐えられないため、Googleは最新の「Cloud TPU」を初めて採用したことも発表した。
BERTの特徴の1つは、1つの言語の学習成果を他の言語に適用できることだ。Webで最も使われている英語での学習モデルを他の言語に適用することで、他の言語での検索結果も改善していく。強調スニペット(説明のスニペットが上部に表示される、通常のリスティングとは形式が逆の特別なボックス)については、既に、“2ダースの国々”(日本が含まれるかどうかは不明)でBERTを採用しており、特に韓国語、ヒンズー語、ポルトガル語の検索で大幅な改善がみられるとしている。
【訂正:2019年10月28日午前5時40分 最後の段落に誤りがあったため、修正しました。】
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
メルカリ、梨の転売疑惑に「盗品の出品は確認されず」 誹謗中傷には利用制限も
-
2
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
3
「iPhone高騰」はこれからも続く? 中国CXMTに近づくApple、メモリ競合へのけん制が不発に終わりそうなワケ【後編】
-
4
「ニューロマンサー」実写ドラマ、Apple TV+で2027年1月配信開始へ
-
5
海外の新作バカゲー「電車アタック」にマンガ家が感心した理由 ブッ飛んだ内容と完成度の高さ、そして“日本”
-
6
「めっちゃカメレオン」公式Discord乗っ取り 担当者PCがマルウェア感染、管理者が全員BANに 現在は復旧
-
7
「こんなのに追われたら……」急斜面もやすやす爆走、中国製の車輪付き四足ロボのデモ動画が話題 最高時速20km超
-
8
暑さ対策が熱い! 「猛暑対策展」で感じた、転んでもただでは起き上がらない日本人のエネルギー
-
9
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
10
スーパーに並んだ「ごちゃごちゃ生成AIポップ」が物議 “看板王”こと、きぬた歯科院長「これはアリ」
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR