
Meta、音声生成AIモデル「Voicebox」発表 ノイズ除去や言い間違い修正、多言語会話など多機能
米Metaは6月16日(現地時間)、新たな音声生成AIモデル「Voicebox」を開発したと発表した。音声の編集、サンプリング、スタイルの設定などを行える。
音声とテキストを入力することで、以下のような音声を出力できる。
- 入力した声で入力したテキストを読み上げる音声クリップを作成する
- 録音した音声から犬の鳴き声やブザー音などのノイズを除去する
- 録音した音声の言い間違いを修正する
- 1つの言語のスピーチを同じ声のまま別の言語に変換する(英語の音声を仏語に、など)
- 1つのテキストを多様な声で読み上げる

Metaは、Voiceboxで将来的にはメタバース内のバーチャルアシスタントやNPC(ノンプレイヤーキャラクター)が自然な声で話せるようになるとしている。また、自分の声のまま(本来は話せない)外国語で会話したり、映画の吹き替えも声優ではなく本人の声で行えるようになるという。
Voiceboxは、「非自己回帰フローマッチングモデル」に基づく音声生成モデル。大規模データを使ってテキストによる音声入力タスクの解決方法を学習することで、コンテキスト内学習を通じて音声タスク全体で単一目的のAIモデルよりも優れたパフォーマンスを発揮するとMetaは説明する。
トレーニングには、英語、フランス語、スペイン語、ドイツ語、ポーランド語、ポルトガル語によるパブリックドメインのオーディオブックの音声とそのトランスクリプト、5万時間分を使った。

Metaは、非自己回帰フローマッチングモデルは、「最先端の自己回帰モデルのTTSより最大20倍の速度で音声を生成する」としている。例として、米Microsoftの「VALL-E」を挙げた。
Metaは論文やサンプル集は公開したが、アプリやソースコードは公開していない。「他の強力な新しいAIイノベーションと同様、このテクノロジーが誤用や意図しない危害をもたらす可能性があることを認識している」からだ。「AIの最先端を前進させるために研究を共有することが重要であると信じているが、オープンさと責任の間の適切なバランスをとることも必要」としている。
TTSの悪用は既に問題になっている。最近ではドレイクとザ・ウィークエンドの声を無断で使った生成型AI楽曲がSpotifyで公開され、話題になった。
関連記事
 日本俳優連合が“生成AI”に提言 「新たな法律の制定を強く望む」 声の肖像権確立など求める
日本俳優連合が“生成AI”に提言 「新たな法律の制定を強く望む」 声の肖像権確立など求める
日本俳優連合が「生成系AI技術の活用に関する提言」を発表した。著作権法の運用見直しやルール作り、「声の肖像権」の確立などを業界や国に求める。 ドレイクとザ・ウィークエンドの声を無断で使った生成型AI楽曲がSpotifyで人気に
ドレイクとザ・ウィークエンドの声を無断で使った生成型AI楽曲がSpotifyで人気に
ドレイクとザ・ウィークエンドの声で歌われる楽曲「Heart On My Sleeve」がSpotifyで公開され、25万回以上再生された。投稿したghostwriterと名乗る人物はこの曲をAIで生成したと説明。「これは始まりに過ぎない」と語った。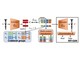 リアルな人間っぽい合成音声を生成するAI 「えー」「あぁ」「うん」なども再現 YouTubeやPodcastで学習
リアルな人間っぽい合成音声を生成するAI 「えー」「あぁ」「うん」なども再現 YouTubeやPodcastで学習
米カーネギーメロン大学に所属する研究者らは、より人間に近い会話の音声合成を生成できる学習モデルを提案した研究報告を発表した。 無限にしゃべる「AIひろゆき」爆誕 本人っぽい声で年中無休YouTubeライブ GPT-3活用で質問にもそれっぽく回答
無限にしゃべる「AIひろゆき」爆誕 本人っぽい声で年中無休YouTubeライブ GPT-3活用で質問にもそれっぽく回答
I音声合成サービスを提供するCoeFontが、ひろゆきさんのようなコメントを、ひろゆきさんのような声で発し続けるAIを開発したと発表。YouTube上で24時間365日質問に答え続けられるという。 Microsoft、3秒分の音声だけでその人の声を真似るAI「VALL-E」のサンプル公開
Microsoft、3秒分の音声だけでその人の声を真似るAI「VALL-E」のサンプル公開
Microsoftは、人間の話す声の3秒分のデータを与えると、その人の声でテキストを読み上げられるようになるAI「VALL-E」を発表した。GitHubでサンプル音声を試聴できる。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PRアイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。