「GPT-4o」は何がすごい? なぜLLMは画像や音声も扱えるの? “マルチモーダル”について識者に聞いた(2/3 ページ)
──GPT-4oでのOpenAIの狙いは何だと思いますか?
椎橋:マルチモーダル化は、本質的により高度な知能を実現するため(=より賢さを追求するため)に重要なステップであるのですが、実は今回のGPT-4oに対するOpenAIの狙いは、そこではないと見ています。
賢さは同じでも、ユーザーインタフェースを変えることでユーザー体験が変わり、普及が加速する、という可能性を世に問いたかった、見せたかった、ということではないか、との見立てです。
これまでOpenAIは、GPT-3、3.5、4と、モデル自体の性能を高めて賢くすることに注力してきました。しかし今回のGPT-4oでは、より賢いモデルを出すのではなく、インタフェースの使いやすさにフォーカスを当てています。
例えば、GPT-4でも音声認識や音声合成と組み合わせれば音声での対話はできました。しかし、それは音声をテキストに変換して、テキストをLLMに入れて、出てきたテキストを再び音声に変換するというものだったので、いくつかボトルネックがありました。処理に時間がかかる、まとまった量の音声をためないとテキストに変換できない、声のトーンを変えられないなどです。そのため人と話すのとは全く違う体験でした。
GPT-4oではこれらの制約を取り払い、平均の応答時間を0.3秒に短縮し、途中で割り込んだり、内容に応じて声のトーンを変えたりできるようになりました。これにより、音声認識に向かって話しかけるのではなく、人と話すような自然な対話が可能になったのです。
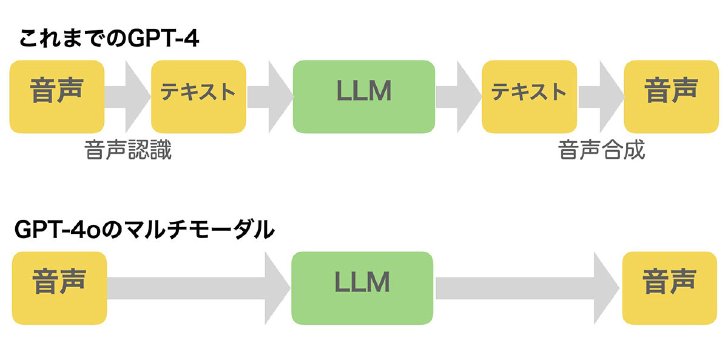 GPT-4における音声対話とGPT-4oでの音声対話の流れの違い
GPT-4における音声対話とGPT-4oでの音声対話の流れの違い
映像についても同様で、ファイルをアップロードしてから質問するのではなく、カメラでリアルタイムに撮影しながら対話ができるようになりました(こちらはユーザーには未公開)。
つまり、OpenAIはGPT-4oで、インタフェースの違いを変えるだけでAIの普及が爆発的に広がる可能性を示そうとしたのだと思います。賢さの追求からインタフェースの使いやすさにシフトしたのが、GPT-4oの特徴といえるでしょう。
──マルチモーダルのLLMは、テキスト入出力のLLMとどう異なっているのでしょう? 音声や画像をどのように処理しているのですか?
椎橋:マルチモーダルLLMの基本的な仕組みは、テキストのLLMとほぼ同じで、ネクストトークン・プレディクション(次のトークンを予測すること)がベースになっています。
違いは、テキスト以外の音声や画像などもトークン化して扱う点です。従来のLLMではテキストだけをトークン化していましたが、マルチモーダルLLMでは音声や画像もトークン化します。
具体的には、まず音声や画像をデジタルデータ化してベクトル化します。ベクトル化は、デジタルデータを特定の特徴を持つ数値の列(ベクトル)に変換することです。
例えば、音声データの場合、波形の特徴量(周波数や強度など)を抽出し、それらを数値の列として表現します。ベクトル化することで、ニューラルネットの入力として扱いやすくなるんです。このベクトルをさらに、LLMのトークンに変換するのがコネクターの役割です。
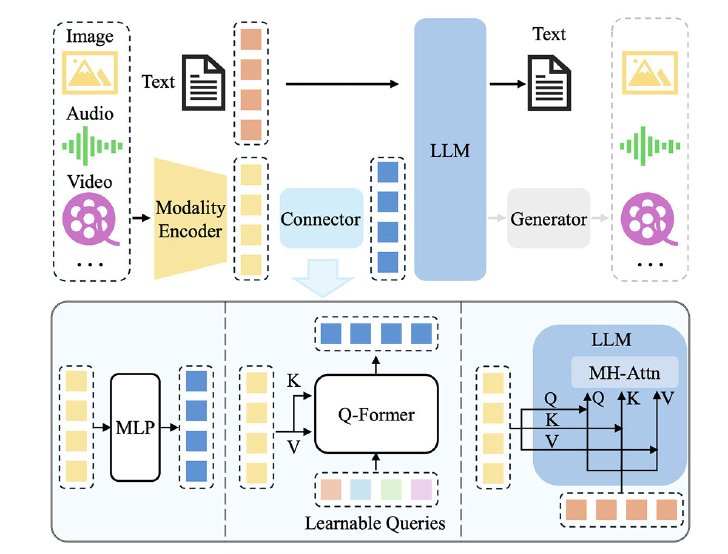 複数のモダリティがベクトル化、トークン変換されて、テキストと同じようにLLMのニューラルネットワークに入っていく(A Survey on Multimodal Large Language Modelsより)
複数のモダリティがベクトル化、トークン変換されて、テキストと同じようにLLMのニューラルネットワークに入っていく(A Survey on Multimodal Large Language Modelsより)
要するに、音声や画像をテキストと同じような入力形式に変換するわけです。こうして音声、画像、テキストは全てトークン化され、それぞれのデータ種別に応じたインデックスを持ちます。例えば、テキストのトークンは1~1万、音声のトークンは1万1~2万、画像のトークンは2万1~3万というような具合で、トークンの種類が区別されます。
LLMは、これらのトークンを入力として受け取り、従来と同様のTransformerのアテンション機構などを用いて処理します。この際、LLMはそれぞれのトークンを統一的に扱います。つまり、テキスト、音声、画像の関係性を学習することができるのです。
そして出力の際は、出てきたトークンの種類に応じて、テキストならそのまま、音声や画像ならデコードして元の形式に戻します。
このように、テキストベースのLLMに、エンコーダーとコネクターを追加することで、LLMにマルチモーダル処理の機構を追加しているわけです。LLMの構造自体は変えずに、入出力を拡張しているのが特徴です。
ただし、音声を切れ目で区切ってトークン化したり、抑揚に合わせて声のトーンを変えたりする際の具体的な仕組みは公開されておらず、詳細は分かっていません。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」サブスクに統合 Max・Team Premiumプラン対象
-
2
Hugging FaceにAI主導のサイバー攻撃 防御もAIで対抗するも、商用モデルは解析拒否で「GLM」採用
-
3
「AIと壁打ちはもう古い」 業務タスクを任せる「Claude Cowork」の落とし穴
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
Google、「NotebookLM」を「Gemini Notebook」に改称 Geminiエコシステムへの統合を強化
-
6
強気値上げで自爆か ClaudeやGeminiに押され「M365 Copilot」は一人負け?:888th Lap
-
7
「AIエージェントの約半数が"戦力外"になる」 なぜ企業は使いこなせない?
-
8
富士通、国内ロボット大手3社と「フィジカルAI」で協業 NVIDIAの技術活用
-
9
日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
-
10
コードなしでもベイズ統計ができる無料の神ツール「JASP」 ~ マウス操作だけでここまでできる
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR