Innovative Tech(AI+)
生成AIが“AI生成コンテンツ”を学習し続けるとどうなる?→「モデル崩壊」が起こる 英国チームが発表
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
英オックスフォード大学や英ケンブリッジ大学などに所属する研究者らが発表した論文「AI models collapse when trained on recursively generated data」は、AIモデルが自己生成したデータで繰り返し学習すると、モデルの性能が低下していく「モデル崩壊」という現象を発見した研究報告である。
 生成AIが“AI生成コンテンツ”を学習し続けるとどうなる?
生成AIが“AI生成コンテンツ”を学習し続けるとどうなる?
ここで言うモデル崩壊とは“生成AIモデルが生成したデータ”が次世代の訓練データを汚染し、世代を重ねるごとに元の真のデータ分布から逸脱して現実を誤認していく退行的プロセスを意味する。
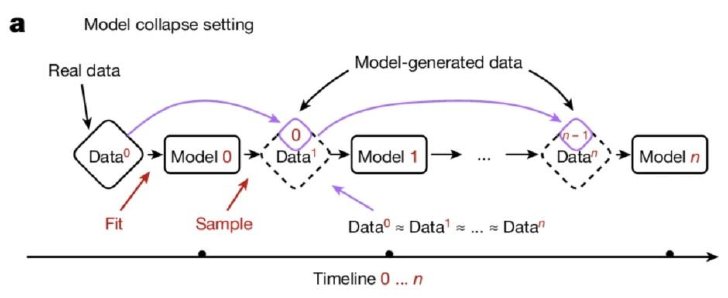 AIが生成したデータを学習し続けると、世代が重ねるごとに性能が低下しモデル崩壊が発生
AIが生成したデータを学習し続けると、世代が重ねるごとに性能が低下しモデル崩壊が発生
研究チームは、大規模言語モデル(LLM)、変分オートエンコーダー(VAE)、ガウス混合モデル(GMM)など、幅広い生成AIモデルを対象に実験を行った。その結果、AIモデルが生成したデータを次世代のモデルの学習に使用し、これを繰り返すと、世代を重ねるごとにモデルの性能が低下していくことが分かった。
LLMを用いた実験では、米Metaが公開している1億2500万のパラメータを持つ「OPT-125m」というモデルを使用。実験ではまず、このモデルを「wikitext2データセット」(Wikipediaの記事から抽出されたテキストデータ)で微調整(ファインチューニング)した。
微調整後、研究者たちは学習済みモデルを使って新しいテキストデータを生成した。次に、この生成したデータセットで新しいモデルを微調整した。このプロセスを繰り返し、各世代のモデルの性能を評価した。
実験は2つの設定で行った。1つ目の設定では、各世代で5エポックの学習を行い、元のトレーニングデータは保持しなかった。2つ目の設定では、10エポックの学習を行い、各世代で元のデータの10%をランダムに保持した。
結果は、両方の設定でモデル崩壊の兆候が見られた。1つ目の設定では、世代を重ねるごとにモデルの性能が大きく低下。2つ目の設定では、元のデータの一部を保持したことで性能低下は緩和されたが、それでも世代を重ねるごとに徐々に性能が低下していった。VAEとGMMを用いた実験でも同様の現象を観察した。
この結果は、LLMなどのAIシステムのトレーニングには「先行者利益」があることを示唆している。長期的な学習を維持するには、元のデータソースへのアクセスを保持し、LLM以外が生成したデータを継続的に利用可能にする必要があるからだ。
研究チームは「AIが生成したWebコンテンツが増加する傾向にあるため、LLMの新しいバージョンを訓練する際、人間が直接作成したデータにアクセスできなくなり、開発がますます困難になるだろう」と指摘している。
一つの解決策として、LLMの開発と展開に関わる各関係者が、生成AIなのか人間が生成したデータなのかの出どころの情報を共有し、コミュニティー全体で協調することが考えられる。
Source and Image Credits: Shumailov, I., Shumaylov, Z., Zhao, Y. et al. AI models collapse when trained on recursively generated data. Nature 631, 755-759(2024). https://doi.org/10.1038/s41586-024-07566-y
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験
-
2
画面操作を“録画”→AIが作業代行 Codexに新機能「Record & Replay」
-
3
AIで要らなくなったSaaS、要るSaaSは、どれ? 日本の「SaaS is dead」の実態
-
4
高級セレクトショップ「バーニーズ」が新品と中古の二刀流 富裕層の「初めての中古購入」を狙うワケ
-
5
「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
-
6
ChatGPT vs. Google検索──どっちで調べるのが学習効果が高い? 8日間の実験で検証した研究
-
7
工数「76%」削減 味の素グループが「経理AIエージェント」導入で先陣を切れたワケ
-
8
チームみらい安野氏「牧歌的なAI開発の時代が終わった」 “ミュトス停止騒動”受け
-
9
月間売上1億円超、“推しAI”アプリ「Zeta」がオタク女子わしづかみ ただし危うさも
-
10
【Pythonで学ぶデータ分析】母平均と母標準偏差をベイズ推定する ~ シュークリームの重さは100gと異なるか?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR