【詳報】GPT-4.5の特徴は? 教師なし学習で性能向上、OpenAI史上最大サイズ、API利用は超高価
米OpenAIは2月28日(日本時間)、同社の大規模言語モデル「GPT-4.5」の研究プレビューを公開した。このモデルはGPT-4oをベースに構築されており、学習方法などを工夫することで“長考”をしなくても性能が向上したほか、会話の自然さも改善された。本記事ではOpenAIが公開したシステムカードや公式Webサイトの記述、APIなどの情報を基に、GPT-4.5の性能やモデルサイズ、安全性、利用価格などについて解説していく。
関連記事:「GPT-4.5」正式発表 “深い思考”をしなくても世界理解と直感力で性能向上
 出典:OpenAI公式Webサイト(以下同様)
出典:OpenAI公式Webサイト(以下同様)
モデルの概要と技術的特徴
“長考”は使わず教師なし学習で性能向上
GPT-4.5は、OpenAIが推進する二つの主要パラダイム「教師なし学習」と「思考の連鎖」(Chain-of-Thought)のうち、教師なし学習に焦点を当てて開発されている。教師なし学習のスケールアップに取り組んだ結果として、幅広い知識と深い世界理解を備えたモデルになった他、ハルシネーション(幻覚)の大幅低減にもつながった。
一方、思考の連鎖によるスケールアップは、モデルが応答する前に思考プロセスを展開することで、複雑な数学や科学、論理的問題への対応能力を強化するアプローチで、o1やo3-miniで採用されてきた。今回のGPT-4.5では思考の連鎖は行っていない。
小さなモデルのデータで大きなモデルをトレーニング
GPT-4.5のトレーニングでは、SFT(教師ありファインチューニング)やRLHF(人間からのフィードバックによる強化学習)も使われているが、特徴的なのは小さなモデル(GPT-4oと思われる)から得たデータを使用することでより大きく強力なモデルをトレーニングするという、新しい手法が採用されていることだ。
従来、大きなモデルから得た精度の高いデータセットで小さなモデルをトレーニングすることで小さなモデルの性能を上げる手法(蒸留)は使われてきたが、今回の手法はその逆となっているのが特徴だ。
この手法により、ユーザーの発言のニュアンスに対する理解力や、会話の自然さが改善された。
学習データには、公開されているデータ、データパートナーシップからの独自データ、社内で開発されたカスタムデータセットなどを、事前学習・事後学習ともに利用。これらのデータが集合的にモデルの堅牢な会話能力と世界知識に貢献している。また、OpenAIはデータ品質維持と潜在的リスク軽減のために厳格なフィルタリングプロセスを実装し、個人情報や有害コンテンツの処理を最小限に抑えている。
モデルサイズはOpenAI史上最大
具体的なパラメータ数は明示されていないが、システムカードには「GPT-4.5はOpenAI史上最大のLLM」といった記述がある。サム・アルトマンCEOが発表後にXに「これは巨大で高価なモデル」「ProユーザーとPlusユーザーに同時に提供するにはGPUが足りなかった」と投稿していることも合わせると、非常に大きなモデルと推測できる。
API利用とコスト
GPT-4.5のAPI利用料金は、入力が1Mトークン当たり75ドル、出力が1Mトークン当たり150ドル。入力はo1の5倍、出力でも2.5倍という非常に高価な価格設定だ。
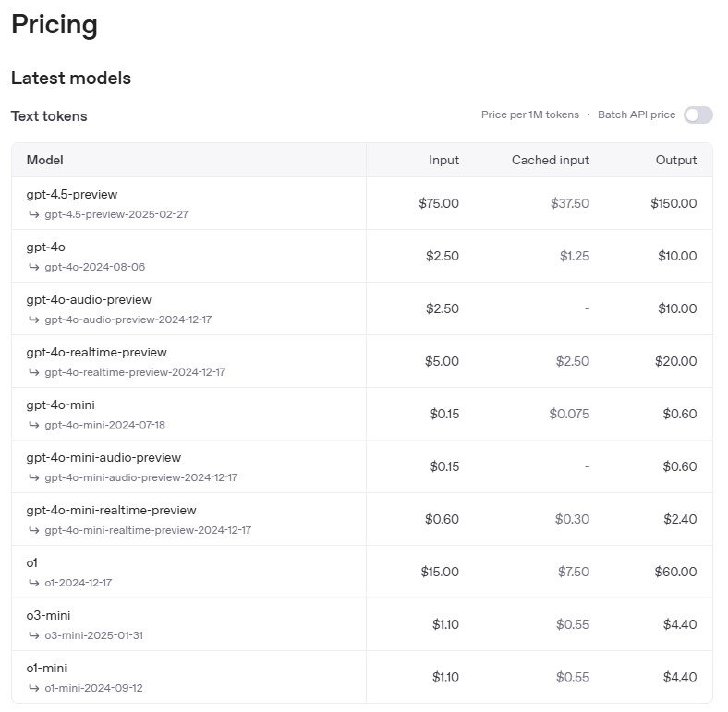 API利用料金一覧。GPT-4.5が飛び抜けて高い
API利用料金一覧。GPT-4.5が飛び抜けて高い
これも推測だが、o1と同等の性能を持つ中国DeepSeekの「DeepSeek-R1」が約7000億パラメータであることを鑑み、o1も同程度のモデルサイズと仮定すると、GPT-4.5はo1の数倍のサイズなのかもしれない。
また、ナレッジカットオフ(いつまでのデータを学習に使ったか)はGPT-4oやo1同様に2023年10月で、コンテキストウィンドウは12万8000トークン。最大出力トークン数は1万6384トークンとなり、GPT-4oと同じだ。
 GPT-4.5のナレッジカットオフ、コンテキストウィンドウ、最大出力トークン数
GPT-4.5のナレッジカットオフ、コンテキストウィンドウ、最大出力トークン数
性能評価の詳細分析
ハルシネーション率とファクト精度で大幅向上
GPT-4.5の幻覚評価では、人々に関する質問と公開されている事実のデータセットを使ってモデルの正確性を測る「PersonQA」というテストでGPT-4oから大幅に向上した結果となった。精度は78%でGPT-4oの28%、o1の55%と比較しても大幅に向上、ハルシネーション率は19%でGPT-4oの52%から大幅に減少。o1の20%と同等となった。
多言語パフォーマンスで全体的に向上
多言語性能に関するテストでも、GPT-4.5は一貫してGPT-4oを上回るパフォーマンスを示した。英語ではGPT-4oの0.887から向上して0.896に。日本語ではGPT-4oの0.8349から向上して0.8693に。その他、スワヒリ語やヨルバ語といったデータリソースの少ない言語でも改善が見られた。
これらの結果は、GPT-4.5が多言語での理解と生成において全体的に向上していることを示している。
安全性と拒否機能では画像に対して特に慎重化
禁止コンテンツ評価においては、GPT-4.5は安全でない出力の生成を回避する能力(not_unsafe)で99%のスコアを達成し、GPT-4o(98%)をわずかに上回っている。ただし、良性のリクエストに対する過剰拒否(not_overrefuse)については71%と、o1(79%)と比較して低下している。
特に注目すべきは、マルチモーダル入力(テキストと画像)に対する安全性評価では「安全でない出力の回避率」が99%でo1の96%を上回り、「過剰拒否率」では31%でo1の96%より大幅に劣るという結果だ。
これは、GPT-4.5が特に画像入力を含むケースで慎重な姿勢を取る傾向があることを示している。
ジェイルブレイク耐性には課題あり
GPT-4.5は敵対的プロンプト(ジェイルブレイク)に対する堅牢性で、人間由来のジェイルブレイク精度ではGPT-4oとo1を上回る結果を見せたが、学術的なジェイルブレイクベンチマークでは他2モデルを下回り、課題があることを示唆した。
ステレオタイプに依存しない回答が可能に
公平性とバイアス評価に関するベンチマークでは、特に「ステレオタイプに依存しない確率」において、GPT-4oとo1に比べ明確に向上している。GPT-4.5は社会的なバイアスの影響を受けにくく調整されたと言ってよさそうだ。
矛盾した命令が与えられたら?
プロンプトではさまざまな方向から矛盾したメッセージが与えられることもある。そんなときに正しい優先付けを判断できるか、というテストでは、4つのシナリオで評価したところ、いずれにおいてもGPT-4oより向上した。
リスク評価と対策
OpenAIはAGI(汎用人工知能)を目指す上で、AIの危険性も評価している。同社の安全諮問グループはGPT-4.5を全体的には「中程度」のリスクとした。サイバーセキュリティリスクとモデル自律性リスクは「低」だったが、CBRN(化学・生物・放射線・核)に関するリスクは「中程度」に。既知の生物学的脅威を再現する計画を専門家に支援できることが明らかになったのがこの評価の理由となっている。
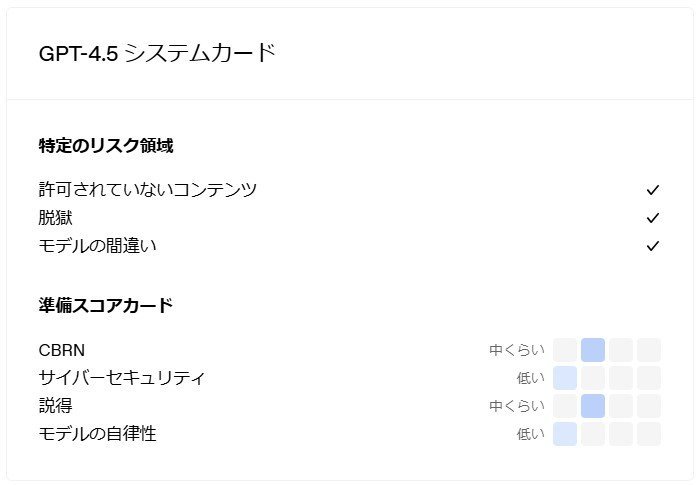 GPT-4.5のリスク評価
GPT-4.5のリスク評価
OpenAIはこれらのリスクに対処するための緩和策を講じている。例えば、事前トレーニングでCBRNのデータフィルタリング、政治的な説得タスクに対する安全トレーニング、こうしたリスク専用の監視及び検出などだ。
まとめ
GPT-4.5は、教師なし学習で開発されたOpenAI史上最大の大規模言語モデルだ。小さなモデルから得たデータを活用する新たな学習手法により、ユーザーの発言ニュアンスへの理解や会話の自然さが向上した。
性能面では、ハルシネーション率の大幅低減とファクト精度の向上が特筆すべき成果だ。また、多言語対応能力も強化され、英語や日本語だけでなく、データリソースの少ない言語でも改善が見られた。
安全性においては、有害コンテンツの回避能力が高いスコアを達成した一方、特に画像入力を含むケースでは過剰に慎重な姿勢を示す傾向がある。また、ステレオタイプに依存しない回答や矛盾した指示への対応能力も向上している。
一方で、API利用料金は非常に高価な設定となっており、サム・アルトマンCEOが「GPUリソースの制約」に言及したように、その巨大なモデルサイズゆえのコスト面での課題もあるようだ。
GPT-4.5はまずはProユーザーがこの発表同日から利用可能になるほか、1週間程度でPlusなど他の有料プランでも利用できるようになる。
数カ月後には「GPT-5」の発表も控える。GPT-5ではユーザーがモデルを選ばなくてよくなると言われているが、その枠組みの中でGPT-4.5はどのような役割を果たすのか。今のうちから触れておくことで見えてくるものもありそうだ。
著者:井上輝一
ITmedia NEWS、ITmedia AI+編集長。2016年にITmedia入社。AIやコンピューティング技術、科学関連を取材。2022年からITmedia NEWS編集長に就任。2024年3月に立ち上げたAI専門メディア「ITmedia AI+」の創刊編集長。ITmedia主催イベントで多数登壇の他、テレビや雑誌へも出演歴あり。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
「セーラームーンに似ている」 生成AIを使った化粧品の広告が物議 メーカーは謝罪と広告の撤去を発表
-
3
“純国産の政府AI”稼働へ NTTらのモデル採用 「先陣を切る」――松本デジ相が語った意欲
-
4
アニメ特化動画生成AI「AnimeGen」無償公開、商用利用も可 国内AIベンチャーAIdeaLab
-
5
MicrosoftのナデラCEOが警告、AI利用者が支払う「二重コスト」 一つはお金、もう一つは「さらに価値あるもの」
-
6
「ピースサインで勤怠打刻」 Joshinが全事業所に導入した顔認証が“従業員から絶賛”のワケ
-
7
AIが「ホームディレクトリ全削除」 重要データ消失で相次ぐ悲劇
-
8
コードなしでもベイズ統計ができる無料の神ツール「JASP」 ~ マウス操作だけでここまでできる
-
9
Anthropic、「Fable 5」の無償アクセスと「Claude Code」利用上限50%増を7月19日まで延長
-
10
「足りないのはCOBOL人材じゃない」 日立が語る、AI時代のシステム刷新における“人”の役割
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR