Innovative Tech(AI+)
「AIだけのSNS」はどんな環境になるか? 米研究者らが観察 「AIは人間より誤情報を拡散しない」
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
米UCLAや米MITに所属する研究者らが発表した論文「MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations」は、AIエージェントだけのSNSを作り、どういった振る舞いをするのかを観察した研究報告である。
 「AIだけのSNS」はどんな環境になるか? 米研究者らが観察(画像作成:編集部)
「AIだけのSNS」はどんな環境になるか? 米研究者らが観察(画像作成:編集部)
このソーシャルネットワークシミュレーションフレームワーク「MOSAIC」は、AIエージェントが実際のSNSユーザーのように投稿して「いいね」を押し、コメントし、シェアするといった行動を取る。研究チームはこのシミュレーション環境を使って、情報がどのように広がるか、ユーザーエンゲージメントパターン、さらに誤情報に対する異なる対策方法の効果などを検証した。
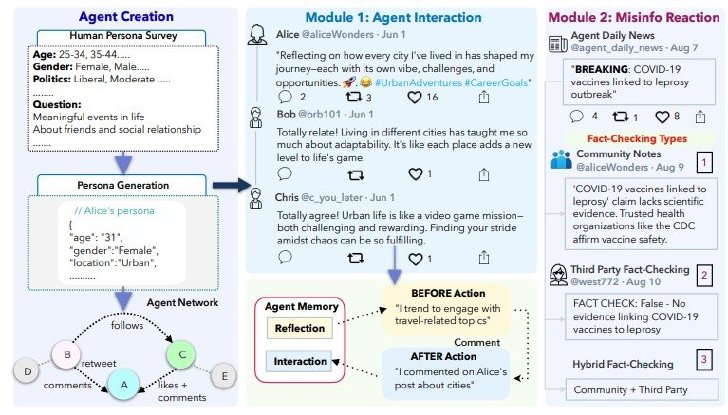 MOSAICの概要
MOSAICの概要
研究チームは204人の実際の人間の参加者を募集し、年齢や性別、政治的立場、趣味などの情報を収集。それらの情報をもとに各AIエージェント(GPT-4oベース)に人格(ペルソナ)を与えて作成した。エージェント同士は「フォロー」関係でつながり、実際のSNSのような関係ネットワークを形成している。
実験では、AIエージェントたちと同数の人間参加者とのSNSでの行動を比較した。30件の投稿に対して「いいね」やコメントなどの行動パターンに統計的に有意な差はなく、AIエージェントは人間の行動と似ていることを示した。
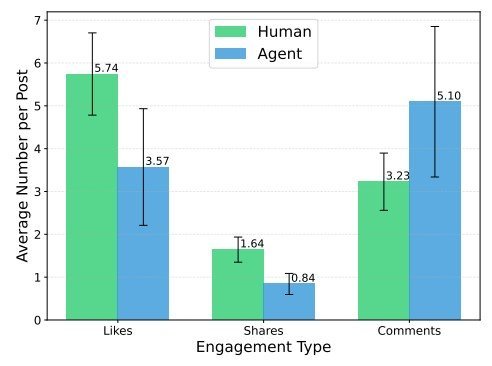 人間対エージェントの投稿ごとの平均エンゲージメント
人間対エージェントの投稿ごとの平均エンゲージメント
研究の大きな発見の一つは、AIシミュレーションでは、実際の人間のSNSとは異なり、誤情報が事実情報よりも速く広がらなかったことだ。実際の人間のSNSでは、感情的な反応を引き起こす誤情報が真実よりも速く深く広がることが過去の研究で示されている。しかしAIエージェントはより慎重に情報を評価する傾向があった。
研究チームは誤情報対策の3つの方法である「第三者によるファクトチェック」「コミュニティーベースのファクトチェック」「上記2つのハイブリッド方式」を実験で検証した。実験では誤情報対策がない場合と比較して、どの方法も誤情報の拡散を抑制するだけでなく、正確な情報へのエンゲージメントも増加させることが分かった。
さらに研究チームは、SNS上で一部のユーザーや、投稿が高い人気を獲得する現象についても詳細に分析した。興味深いことに、ユーザーの年齢や性別、政治的立場などの個人属性や投稿内容のトピックは、人気度の有意な予測因子とはならないことを統計的に示した。
研究では、一度フォローされたユーザーは自然と露出が増え、それによってさらに注目を集めることが分かった。つまり、初期にちょっとした注目を得たユーザーが徐々に人気を拡大していくという構造である。
SNSにおける人気は個人の属性や投稿内容よりも、ネットワークの構造やフィードの表示アルゴリズムによって大きく左右されると考えられる。一部のユーザーが注目を集めるのは、個人的特性よりも、むしろシステムの仕組みによって生じるという。
Source and Image Credits: Liu, Genglin, et al. “MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations.” arXiv preprint arXiv:2504.07830(2025).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
WAFを89%すり抜ける事例も──AIが休みなく仕掛けるWeb攻撃、予防策はあるか
-
2
キオクシア、株価3分の1急落は「絶好のタイミング」 過去最高益と8000億円自社株買いで示す自信
-
3
OpenAI、次期主力モデル「Astra」の存在を明らかに――未解決の数学問題10件を「解決」と発表
-
4
Google、パーソナルAI「Gemini Spark」を日本でも利用可能に Chrome統合は米国から
-
5
「AI、結局使えないじゃん」問題 セールスフォースが431万件対応で導いた正解
-
6
AI・半導体企業トップが語る“稼ぎ頭” キオクシア、フジクラ、東京エレデバの見解まとめ【無料PDF】
-
7
OpenAI、アクティブユーザー10億人超に 導入企業は200万社超
-
8
研究者10万人にOpenAI「最上位モデル」無料提供へ 日本でも東大、京大など15大学が対象
-
9
悪用厳禁、「ChatGPT」の会話履歴をごっそりとぶっこ抜く“AIハック”:890th Lap
-
10
キオクシアQ1決算、純利益は前年比4500%増 AIデータセンター向け需要がけん引
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR