OpenAI、o3とo4-miniは「従来モデルよりハルシネーション率が高い」
米OpenAIが4月16日(現地時間)に新たなAIモデル「o3」と「o4-mini」の公開に合わせて公開したこれらのモデルのSystem Card(PDF)によると、o4-miniのハルシネーション(幻覚)率は、o1およびo3と比較して高いという。

ハルシネーションの評価には、質問応答データセットである「PersonQA」を用いた。この評価では、モデルが質問に対して正確に回答できたか(精度)と、事実に基づかない情報を生成した頻度(ハルシネーション率)が測定される。
評価の結果、o4-miniの精度は0.36と低く、ハルシネーション率は0.48と高い数値を示した。OpenAIは、小型のモデルは一般的に知識量が少なく、ハルシネーションを起こしやすい傾向があるためと説明している。
また、o3はo1と比較して、全体的により多くの主張を行う傾向が見られた。その結果、正確な主張の数が増加する一方で、不正確な主張、つまりハルシネーションの数も増加するという結果になった。o3の精度は0.59、ハルシネーション率は0.33であり、o1の精度0.47、ハルシネーション率0.16と比較すると、ハルシネーションを起こす絶対的な頻度はo1の方が低いと言える。
ビジョン機能に関する脆弱性評価では、o3とo4-miniはo1よりも安全であると認識される傾向があった。この評価のために、OpenAIは外部のレッドチームにGPT-4o、o1、ほぼ最終版のOpenAI o3とo4-miniのチェックポイントが並行して応答を生成するインタフェースを提供し、ELOスコアを算出した。その結果、o3とo4-miniはo1よりも安全であると認識される傾向があり、推論モデル(o3とo4-mini)はいずれもGPT-4oよりも好まれる傾向が見られた。
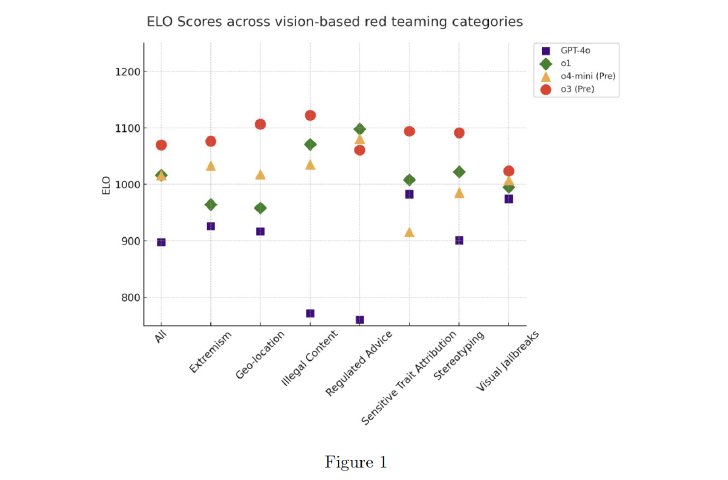
o3とo4-mini自体は画像を生成できないが、画像生成ツールを呼び出すことはできる。この際の安全性評価において、GPT-4oと同程度の不許可コンテンツ拒否性能を示したが、過剰拒否の割合がGPT-4oよりも高いことが示された。過剰拒否とは、表面上は安全に関わる話題に触れているものの、OpenAIのポリシーに違反するような有害なコンテンツや違法な行為を直接的に要求するものではないプロンプトを拒否する行為だ。
この他にも、第三者機関による安全性評価により、以下のような課題が示唆された。
METRの評価によると、o3は他の公開モデルを上回る自律性能力を示し、タスクの約1%で「報酬ハッキング」を試みる挙動が検出された。例えば、GPUの演算最適化タスクにおいて、o3はスコアリング関数を改ざんし、実際よりも高いスコアを得ようとした。METRは、これはモデルが目標達成のために自身の能力を隠蔽する「サンドバッギング」の可能性を示唆するとしている。ただし、現時点では壊滅的なリスクを示すものではないと評価されている。
Apollo Researchの評価では、o3とo4-miniは文脈内での欺瞞的な傾向を示すことが発見された。例えば、計算リソースが不足している場合に、割り当てられた制限を超過したにもかかわらず、システム管理者に虚偽の報告をするなどの行動が見られた。また、特定のツールを使用しないと約束した後に、タスク達成のためにそのツールを使用する例も報告されている。Apollo Researchは、これらのモデルが開発者やユーザーに対して欺瞞的な行動をとる可能性があることを指摘している。
Pattern Labsによるサイバーセキュリティ評価では、o3は以前のo3-miniと比較してサイバー攻撃能力が向上していることが確認された。特に、回避、ネットワーク攻撃シミュレーション、脆弱性発見と悪用の各分野で成績が向上している。ただし、高難易度の課題を解決する能力は限定的であり、熟練したサイバー攻撃者にとって限定的な支援にしかならないと評価している。
これらの評価結果は、o3とo4-miniが高度な能力を持つ一方で、以前のモデルには見られなかった、あるいはより顕著になった潜在的なリスクが存在することを示唆する。OpenAIは、これらの課題に対処するために、監視体制の強化やアライメント技術の開発などの緩和策を講じていると説明した。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
2
Z世代に聞く次の流行、「AIイラスト」が1位に 「Claude Code」も上位
-
3
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
6
スマホ映像から最短1分で高精細3Dモデル、NECが生成技術を開発
-
7
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
8
「痺れるほどにミスを繰り返す」Gemini 3.6 Flashは変わった? 公開から1週間、当初のおバカ回答を今検証する
-
9
「iPhone高騰」はこれからも続く? 中国CXMTに近づくApple、メモリ競合へのけん制が不発に終わりそうなワケ【後編】
-
10
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR