NVIDIA、日本語データセットを公開 日本文化など反映した合成ペルソナ600万件 商用利用も可能
米NVIDIAは9月23日(現地時間)、日本語の合成データセット「Nemotron-Personas-Japan」を、Hugging Face上で公開した。日本の文化や人口統計などを反映したペルソナ600万件を含んでおり、データやシステムを国内インフラ内で完結させる「ソブリンAI」の開発での利用を想定する。ライセンスは、商用利用も可能な「CC BY 4.0」。
Nemotron-Personas-Japanの開発には、同社の企業向け合成データ作成サービス「NeMo Data Designer」を利用した。同データセットは、日本語で記述された600万件のペルソナを含んでおり、総トークン数は約14億。日本の人口統計や地理的分布、文化的特性などを反映するよう設計しており、各ペルソナには約95万の固有名や、1500以上の職業カテゴリーなどを割り当てた。
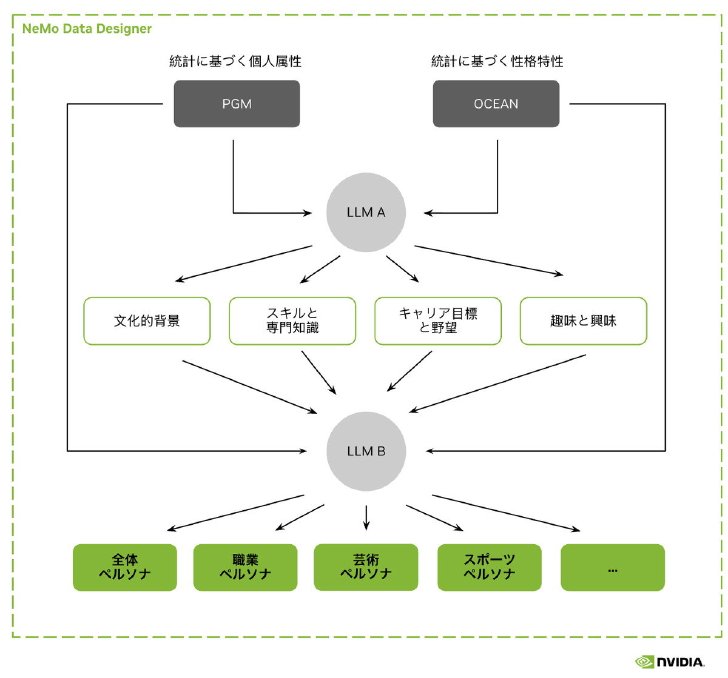 NeMo Data Designerによる合成データ作成の概要(出典:公式ブログ、以下同)
NeMo Data Designerによる合成データ作成の概要(出典:公式ブログ、以下同)
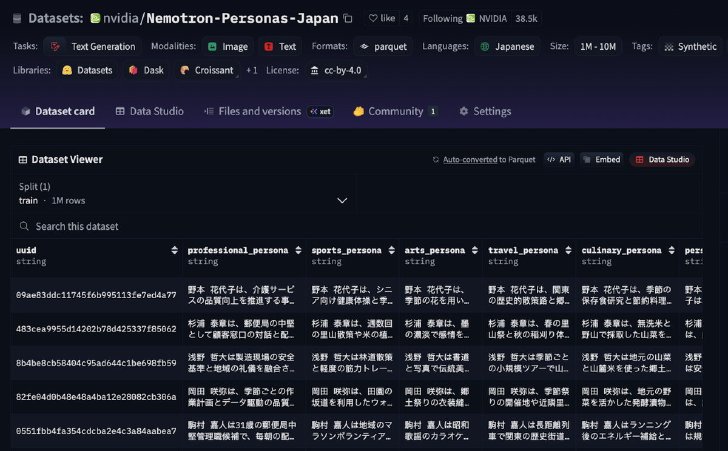 データセットの内容
データセットの内容
なお、同データセットは日本の公的な人口・労働関連の統計データに基づいている一方、全てのペルソナは合成によって作成しているため、個人を特定できる情報は含まれていない。また、個人情報保護法(PIPA)の要件も満たしているという。
同データセットは、ソブリンAIの開発での利用を想定している。例えば、日本の文化的な背景を踏まえた回答ができるAIアシスタント向けのトレーニングデータの作成や、AIシステムが日本の地方と都市、異なる年齢層、教育水準の人々に対し、どのように機能するか評価するためなどに利用できるという。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
2
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
3
ローカルLLMは本当に手元で動くのか? ハードウェアとモデルの現実的な選び方【2026年春】
-
4
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
5
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
6
ループエンジニアリングとは? チャットとAIコーディングの往復から卒業する新しい開発スタイル
-
7
【解説】キオクシアなぜ急成長? 半導体メモリって何? AIブームを見通すための基礎知識
-
8
東電出資に意欲 孫正義氏が「国内データセンター誘致」で狙うインフラ戦略
-
9
Flashの再来? Figmaの新機能「Figma Motion」に懐かしいとの声 アニメーション生成するAI機能も
-
10
AIコーディングはなぜ後から苦しくなるのか? 技術負債に続く「理解負債」「認知負債」という新たな落とし穴
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR