小林啓倫のエマージング・テクノロジー論考
パラメータ数は1兆超──“超巨大”なLLM「Qwen3-Max」は何がすごいのか? 中華製フラッグシップAIの現在地(1/3 ページ)
中国Alibabaが9月に発表した、同社のLLM「Qwen」シリーズの新たなフラッグシップモデル「Qwen3-Max」。同モデルは1兆超パラメータを持ち、特にタスクを自律的に実行するエージェント能力が強みだ。AI分野の中心が、タスク特化型AIから生成AI(チャットbot)、AIエージェントへと移りつつある中、Qwen3-Maxはどのような存在といえるのだろうか。
 “超巨大”なLLM「Qwen3-Max」は何がすごいのか?
“超巨大”なLLM「Qwen3-Max」は何がすごいのか?
「Qwen3-Max」の仕組みは?
まずは、このモデルの概要をまとめておこう。Qwen3-Maxは、Alibabaが中国の浙江省杭州市で開催した年次イベント「Apsara Conference」で発表したAIモデル。記事時点で同社最大規模のAIモデルであり、開発には36兆トークンという膨大な学習データを使ったという。
パラメータ数は1兆以上で、119の言語に対応している。米OpenAIなどの競合他社はこれらの指標について明確な数値を示していないが、Qwen3-Maxの性能は、他の先端AIモデルに匹敵するか、それを上回るものと考えられている。
この巨大な規模を実用的なレベルで実現するために採用したのが、MoE(Mixture of Experts、エキスパート混合)と呼ばれるアーキテクチャだ。
これまでの大規模なAIモデルでは、計算処理が膨大になるという問題が指摘されてきた。例えば1兆パラメータのモデルでは、1つの質問に答えるだけでも全パラメータを通す必要があり、そのままではレスポンスが非常に遅く、コストも高くなってしまう。これは特に、企業内で大規模な利用を想定している場合には大きな課題となる。
しかしQwen3-Maxでは、モデル内に小規模な128の専門家(エキスパート)モデルを組み込んでおり、1つの質問に対して8つの専門家モデルを選択・活用する。
各専門家モデルは、数学やプログラミング、言語翻訳など特定の種類のタスクや知識領域に特化しており、実際の処理では、8つの専門家モデルのアウトプットを統合して最終的な答えを生成する。この仕組みにより、推論時の計算リソースを大幅に節約し、運用効率を高めているという。
またAlibabaは、OpenAIのAIモデル「GPT-5」と同様、Qwen3-Maxに「Instruct」(非思考)と「Thinking」(思考)の2モードを用意する方針を示している。InstructはAPIとAlibabaのチャットAI「Qwen Chat」で提供中で、Thinkingは今後順次提供する予定だ。
Instructは標準的な指示の実行や、コーディング向けに設計しており、高速な応答が必要なタスクに適している。一方Thinkingは、複雑な論理推論や、外部ツールを活用するエージェント処理に特化したバージョンだ。同モードは思考時間をより長くすることで、数学的推論などの性能を強化。ベンチマークでは、米国数学オリンピック予選問題(AIME 2025)で100%の正答率を達成している。
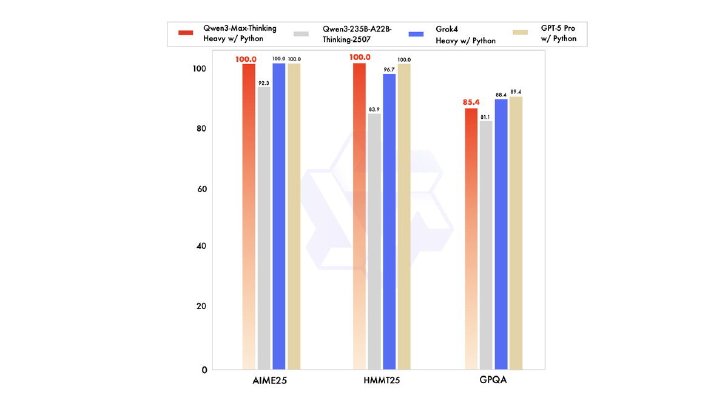 「Thinking」モードのベンチマークの結果(出典:Alibaba公式ブログ、以下同)
「Thinking」モードのベンチマークの結果(出典:Alibaba公式ブログ、以下同)
この切り替え可能な設計により、ユーザーはタスクの複雑さに応じて、計算リソースを効率的に配分できる。前述のMoE同様、巨大なモデル規模と効率性・省コストを両立させる工夫がなされているわけだ。
Copyright © ITmedia, Inc. All Rights Reserved.
小林啓倫のエマージング・テクノロジー論考
生成AIやメタバース、新たなサイバー攻撃など、テクノロジーの進化が止まらない。少しずつ生活の中に浸透し、その恩恵を預かれることもある一方、思いもよらない問題を生み出すこともある。このコーナーでは、さまざまな分野の新興技術「エマージング・テクノロジー」について、小林啓倫氏が解説する。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
2
AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
-
3
【解説】キオクシアなぜ急成長? 半導体メモリって何? AIブームを見通すための基礎知識
-
4
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
5
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
6
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
7
東電出資に意欲 孫正義氏が「国内データセンター誘致」で狙うインフラ戦略
-
8
ループエンジニアリングとは? チャットとAIコーディングの往復から卒業する新しい開発スタイル
-
9
AIコーディングはなぜ後から苦しくなるのか? 技術負債に続く「理解負債」「認知負債」という新たな落とし穴
-
10
Flashの再来? Figmaの新機能「Figma Motion」に懐かしいとの声 アニメーション生成するAI機能も
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR