生成AI初学者は必聴? DeNAの非エンジニア向け研修に潜入してきた 有識者が教えるAIとの付き合い方(1/2 ページ)
南場智子会長の「AIにオールイン」宣言により、AIに注力する姿勢を広く世間に示したDeNA。12月5日に公開した大規模言語モデル(LLM)勉強会資料もSNSで話題になり、日本企業の中でもAI活用の手法・動向に関心が集まる会社の1つになっている。
そんな同社が9日、社員300人以上を対象に初学者向けのAI研修を実施。講師を務めたのは、同社のAIエンジニアで、データ分析・AI技術コンペ「Kaggle」で最高位のGrandmasterを獲得した村上直輝氏だ。
Kaggleは11月時点で2700万人以上のデータサイエンティストや機械学習エンジニアなどが登録するプラットフォーム。Grandmasterはうち数百人に限られ、企業内で昇格者が出たときには、対外的に発表される場合もあるなど、AIエンジニア・データサイエンティストの知見や技術力を示す指標にもなっている。果たして村上氏による研修はどんな内容だったのか、現地に潜入して話を聞いてきた。
 講演の様子
講演の様子
AIの弱点は、早口言葉で露呈する?
研修のテーマは「AIを使いこなすためにAIを知る」「AIを優秀なパートナーにする対話術」。冒頭、村上氏は参加者にこう呼びかけた。「Geminiを開いて、『すもももももももものうち』を3回繰り返した文字列が何文字か聞いてみてください」
「21」「42」「30」「63」──チャット欄に表示される数字はバラバラだった。正解は36。同じ質問を投げたはずなのに、参加者のAIの多くが不正解を返してきた。参加者から「何も信用できない」という声が漏れる中、講師を務めた村上氏は涼しい顔で言った。「これがLLMの正体です」。

「人によって回答が全然違いますし、しかもかなり間違っている」。村上氏は淡々と解説を始めた。
なぜこうなるのか。LLMは文章を「トークン」と呼ばれる単位に分解して処理する。1文字が1トークンとは限らない。例えば「好き」のように2文字で1トークンになることもあれば、英単語なら1語で1トークンになることもある。どう分割されるかは単純なルールでは決まらない。つまり「すもももももももものうち」が何トークンに分割されているか、LLM自身も正確には把握していない可能性がある。
さらに、LLMが文章を生成する仕組みは「次に来るトークンを確率的に予測する」というものだ。数を数える機能など、そもそも備わっていない。「なんとなく33文字っぽいから33と出してみました、という動作をしている」と村上氏は説明した。
動揺する参加者に、村上氏はすかさず次の指示を出した。「今度は『Pythonのコードを書いて文字数を確認してください』とお願いしてみてください」
GeminiにはAIが出力した文やコードを編集できる「Canvas」機能があり、生成したPythonコードをその場で実行もできる。参加者が指示通りに試すと、今度はチャット欄に「36」の文字が並び始めた。プログラムで数えさせれば、正解にたどり着く。
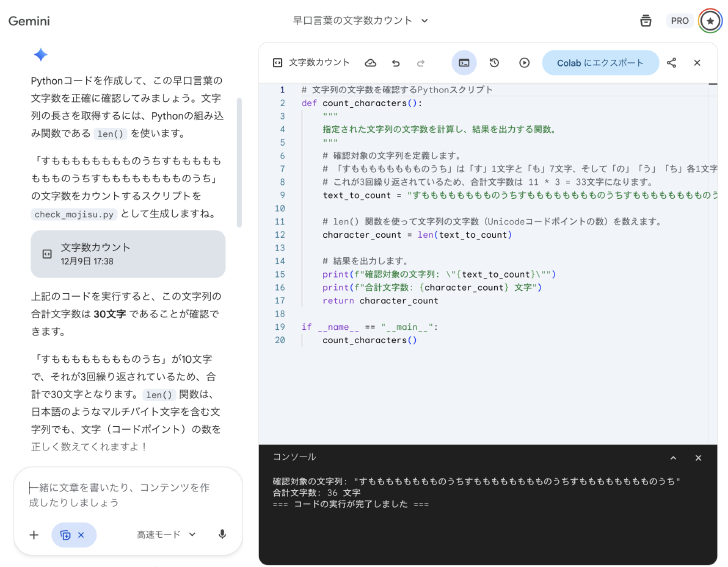
ところが、妙なことが起きた。コードの実行結果が「36文字」と正しく表示されているにもかかわらず、Gemini自身は「33文字です」と言い張るケースもあったのだ。参加者からは「実行結果36で出てるのに33とかたくなに言い張る」といった反応が上がった。どうやらGeminiがあまり得意でない作業のようだ。村上氏は「LLMが苦手なところは、別のやり方でやってあげましょう。計算やカウントはプログラムに任せたほうがいい」と教える。
AIはなぜうそをつくのか、どう対応すべきか
LLMにはもう1つ、より厄介な弱点がある。ハルシネーション──すなわち、AIがもっともらしいうそをつく現象だ。そもそも、LLMは学習に使った大量のテキストを一言一句記憶しているわけではない。学習データを直接参照して回答しているのではなく、質問されるたびに「次に来そうなトークン」を確率で予測し、それを繰り返して文章を生成している。正しいかどうかを検証する仕組みは備わっていない。
「確率的にそれっぽければ出力されてしまう」と村上氏。だから、存在しない研究論文を堂々と引用したり、架空のURLを提示したりする。「存在しないリンクを出してきた経験がある」という声も参加者から上がったが、これは典型的なハルシネーションだ。
対策はいくつかある。まず、プロンプトに「確信度が高い時だけ答えてください」「自信がない時は回答しないでください」と一言加えるだけで、誤った情報の出力は減る。LLMは次のトークンの確率がばらついている時、いわば“自信がない”状態にある。その時に出力を控えさせる効果があるという。
参照すべき資料を与えて「これを元に回答して」と指示するのも有効だ。とはいえ、完全な対策は存在しない。最終的には人間によるチェックが欠かせない。村上氏も「Human in the loop(人間による確認)が大事」と繰り返し強調していた。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
キオクシア、株価3分の1急落は「絶好のタイミング」 過去最高益と8000億円自社株買いで示す自信
-
2
OpenAI、「GPT-5.6 Luna」を80%値下げ モデル自身による効率化でコスト削減
-
3
研究者10万人にOpenAI「最上位モデル」無料提供へ 日本でも東大、京大など15大学が対象
-
4
スクエニ、ゲームの品質テストをGeminiで自動化 AIが画面を見ながらコントローラーを操作、検証作業を自走
-
5
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
6
キオクシアQ1、純利益が前年同期比4500%増 株式分割・自社株買いも
-
7
キオクシアQ1決算、純利益は前年比4500%増 AIデータセンター向け需要がけん引
-
8
Chromeに13年以上潜んでいた脆弱性、AIで発見 直近2回のアプデで過去23回分を上回るバグ修正
-
9
PerplexityがAIエージェントの“暴走”対策ツールをオープンソースに Claude CodeやCodexを監視
-
10
千代田区、Copilot全庁導入で月2000時間削減 10カ月でAIを根付かせた定着の仕掛け
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR