Google、エージェント特化の「Gemma 4」をApache 2.0で公開
米Googleは4月2日(現地時間)、高性能オープンモデル「Gemma 4」をリリースした。最大の特徴は、高度な推論や多段階の計画、エージェント型のワークフローに特化して設計されている点と、Gemmaシリーズとして初めて商用利用の自由度が高いApache 2.0ライセンスで公開されたことだ。
 (画像:Google)
(画像:Google)
先代の「Gemini 3」と同じ研究と技術に基づいて構築されており、テキストに加えて画像や動画の処理に対応するほか、システムプロンプトや関数呼び出しをネイティブにサポートしている。
提供されるモデルは、モバイルやIoTデバイスでの実行に向けてメモリ効率を最大化した「E2B」(Effective 2B)と「E4B」、パソコン上で高速な推論を実現する「26B MoE」(Mixture of Experts)、ファインチューニングの強力な基盤となる「31B Dense」の4種類。
小型のE2BとE4Bは音声入力もネイティブに処理でき、大型モデルでは最大25万6000トークンという長大なコンテキストウィンドウを扱える。
140以上の言語をサポートしており、ベンチマークでも業界をリードする成績を収めている。例えば、「Arena AI」のテキストリーダーボードでは31Bモデルがオープンモデルとして世界第3位、26Bモデルは自身の20倍の規模のモデルより上位の第6位にランクインしている。
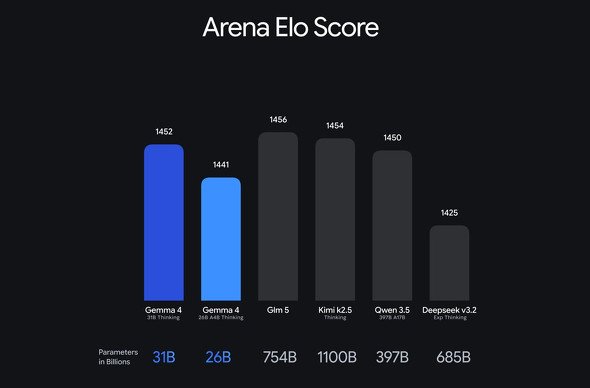 Arena AIベンチマーク(画像:Google)
Arena AIベンチマーク(画像:Google)
利用方法としては、「Google AI Studio」「Kaggle」「Hugging Face」などのプラットフォームからモデルをダウンロードできるほか、「Ollama」や「LM Studio」などのツールを使ってローカル環境で実行可能だ。また、「Vertex AI」「Cloud Run」「Google Kubernetes Engine(GKE)」「Cloud TPU」などのクラウド環境に展開できるという。Cloud RunではBlackwellアーキテクチャのGPUを活用した推論が可能であり、GKEでは新たな「Agent Sandbox」を利用することで、エージェントによるコード生成やツール呼び出しを安全かつ分離された環境で高速に実行できるほか、Sovereign Cloudの活用による厳格なデータ主権要件にも対応している。
また、Androidの「AICore Developer Preview」を通じて「Gemma 4」のアーリーアクセスが開始された。現在Gemma 4向けに書いたコードは、年内に登場予定の「Gemini Nano 4」搭載端末でも自動的に動作する見込みだ。
米NVIDIAによると、Gemma 4はNVIDIAのGPU向けに最適化されているという。RTX搭載PCや「DGX Spark」、エッジ向けの「Jetson Orin Nano」などでローカルのAIエージェントを効率的に実行でき、NVIDIAのTensorコアを活用することで高いスループットと低遅延での推論が可能になると説明している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
人型ロボットが工場で稼働する様子を6日間生配信、作業成功率99.99%をうたう 中国メーカー
-
3
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
4
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
5
復活した「Fable 5」 米政府からのオーダーに対して、Anthropicはどう対策したのか
-
6
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
7
国内大手ロボットメーカー3社が協力、「フィジカルAI」向けデータセット構築へ
-
8
任天堂、生成AIに対する考えを明かす 古川社長「ゲーム開発とAI技術はもともと近い」一方……
-
9
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
10
Anthropicの営業はAIエージェントをこう使う! 日本法人メンバーが明かす手の内
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR