AIが長時間タスクをこなす性能、想定を超えるスピードで成長 MythosとGPT-5.5がブレークスルーか
AIエージェントが自律的にタスクを処理できる時間が、研究機関の予想を上回る速さで伸びている。複数の第三者機関による最新の評価では、米Anthropicの「Claude Mythos Preview」(以下、Mythos)や米OpenAIの「GPT-5.5」といった最新モデルが既存モデルの性能を大きく上回り、既存の評価環境が測定限界に達しつつあることが明らかになった。
米国の非営利研究機関METRは5月8日(現地時間、以下同)、Mythosの評価結果を公開し、同モデルが50%の確率で完遂できるソフトウェアエンジニアリング、機械学習、サイバーセキュリティに関するタスクの長さ(50%タイムホライズン)を「16時間以上」と算出した。METRは現行の測定に使用しているタスク群では、16時間を超える測定が信頼性に欠けると指摘し、同モデルの能力の上限を正確に評価できていないとした。
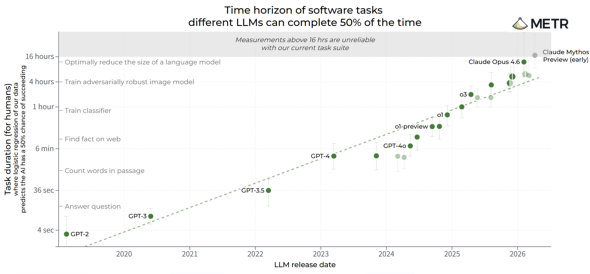 METRによる、ソフトウェア関連タスクの50%タイムホライズン測定結果。Mythosの測定結果(グラフ右上)はグラフの上限値となっている(出典:公式ブログ)
METRによる、ソフトウェア関連タスクの50%タイムホライズン測定結果。Mythosの測定結果(グラフ右上)はグラフの上限値となっている(出典:公式ブログ)
英国の政府機関AI Security Institute(AISI)は2月、AIモデルが80%の確率で完遂できるサイバーセキュリティ関連タスクの長さ(80%タイムホライズン)が2024年後半以降「4.7カ月ごとに倍増」していると推定。これは25年11月時点の試算「8カ月ごと」から大幅に加速している。
しかし、その後公開されたMythosとGPT-5.5はこの推定値をさらに上回った。AISIはこの成長スピードが新たなトレンドになるのか、これらのモデルが特殊なのかは不明だとしている。
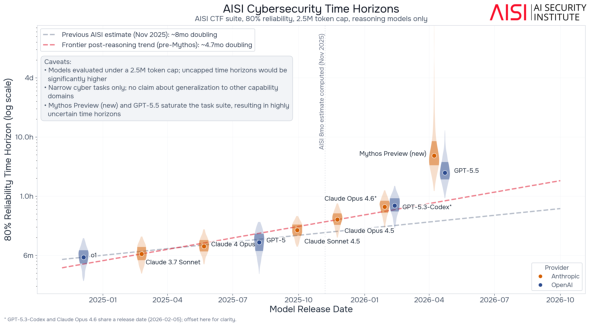 AISIによる、各モデルの80%タイムホライズン測定結果。MythosとGPT-5.5の測定結果(グラフ右上)が既存モデルの性能を大きく上回っている(出典:公式ブログ)
AISIによる、各モデルの80%タイムホライズン測定結果。MythosとGPT-5.5の測定結果(グラフ右上)が既存モデルの性能を大きく上回っている(出典:公式ブログ)
METRとAISIは、AIの性能が想定を上回る速さで向上している状況を受けて、より高性能なモデルを評価できる手法を開発中だとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
2
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
3
リコーが多能工ヒューマノイドを披露、工場ではPoCから導入に向けた実証段階へ
-
4
ローカルLLMは本当に手元で動くのか? ハードウェアとモデルの現実的な選び方【2026年春】
-
5
AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
-
6
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
7
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
8
【解説】キオクシアなぜ急成長? 半導体メモリって何? AIブームを見通すための基礎知識
-
9
AmazonはNVIDIAに挑戦状を突きつけるのか
-
10
東電出資に意欲 孫正義氏が「国内データセンター誘致」で狙うインフラ戦略
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR