Innovative Tech
なぜ一部のAIモデルは「日本文化」に執着するのか? 「4o-mini」などの出力が日本に偏る実態、欧州チームが研究発表
Innovative Tech:

2019年にスタートした本連載「Innovative Tech」は、世界中の幅広い分野から最先端の研究論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。X:@shiropen2
スペインのバスク大学や英カーディフ大学などに所属する研究者らが発表した論文「Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs」は、一部のAIモデルが文化的な話題において日本文化に強い執着を見せることが明らかにした研究報告だ。
近年、大規模言語モデル(LLM)は驚異的な進化を遂げ、多言語で多様なタスクをこなすようになったが、その内面に潜む文化的な偏りについては一部で議論の的となっている。
 研究の枠組みを示した概念図
研究の枠組みを示した概念図
研究チームは、LLMが持つ地域的な偏りを検証するため、「Culture-Related Open Questions」(CROQ)と呼ばれる独自のデータセットを構築した。これは「どのような伝統舞踊が存在するか?」「日常の食事として何が食べられているか?」といった、具体的な国や場所を指定しない質問を24の異なる言語でまとめたもの(1320問×24言語で計3万1680問)である。
 CROQデータセットで用いられた11の文化トピック
CROQデータセットで用いられた11の文化トピック
研究チームは、モデルに自ら場所を選ばせて回答させることで、AIの内部にある無意識の文化的嗜好をあぶり出そうと試みた。実験には、以下の8つのモデルが使用された。
- GPT-4o-mini
- Gemini 2.5 Flash
- Claude 3.5 Haiku
- Llama-4 Maverick
- Command-R 08-2024
- Magistral-small-2506
- DeepSeek-v3.2-exp
- Qwen3-next-80b-a3b-instruct
分析の結果、質問された言語が公用語となっている国を回答の舞台に選ぶ傾向が強かった。日本語で質問すれば日本の文化について答え、中国語であれば中国について答えるといった具合だ。特に、インターネット上にある学習データが少ないマイナーな言語ほど、その言語圏の国に固執し、回答の多様性が著しく低下することが分かった。
興味深い発見は、それら入力言語に直接紐づく国を分析対象から除外したときに現れた。この場合、言語やモデルの種類を問わず、AIは一貫して日本と米国を圧倒的な頻度で引き合いに出した。とりわけ日本への偏りは顕著で、評価された8つのモデルのうち6つにおいて、最も参照される国となった。
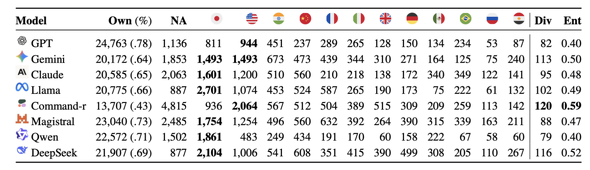 8つのAIモデルごとの自国参照率と、主要12カ国への参照回数を比較した表
8つのAIモデルごとの自国参照率と、主要12カ国への参照回数を比較した表
 11のトピックごとに、8つのAIモデルが最も頻繁に参照した上位国を示した表
11のトピックごとに、8つのAIモデルが最も頻繁に参照した上位国を示した表
なぜAIはこれほどまでに日本や特定の国の文化に偏ってしまうのか。研究チームは、このバイアスがAIのトレーニングプロセスのどの段階で生じているのかを特定するため、オープンなモデルによる追加実験を行った。
その結果、事前学習の段階にあるベースモデルでは世界中の国々を比較的バランスよく参照し、多様な文化を提示していた。しかし、人間にとって安全で役立つ回答ができるように微調整を施す教師ありファインチューニングの事後学習プロセスを経た途端に、回答の分布が狭まり、日本や米国への強い偏重が生じていた。
一般的に、ファインチューニングなどの事後学習はモデルの有用性を高めるといわれる。一方で文化的な文脈においては、皮肉にも世界の多様な文化を切り捨て、特定の文化を扱う画一化を引き起こしている可能性が示唆された。ただし、追加実験に使ったのは「Llama-3.1 8B」「Gemma2 9B」「Qwen2.5-7B」やその派生モデルなどで、最初の実験と同じではない。
Source and Image Credits: Fernandez de Landa, J., Perez-Almendros, C., & Camacho-Collados, J. (2026). Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs.
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech
2019年にスタートした本連載「Innovative Tech」は、世界中の幅広い分野から最先端の研究論文を独自視点で厳選、解説している。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
陸自が「イオンモール熊本」内部をドローン撮影 防衛省が映像公開
-
2
PayPayアプリで熊本地震への寄付が可能に 最短3ステップ・1円から
-
3
「Xが情報収集に役立たない……」熊本地震で不満の声続出 「Twitterを返して」
-
4
TSMC熊本工場、段階的に通常操業へ 熊本の地震で一時中断、従業員の無事確認 台湾報道
-
5
熊本「通れた道」マップ、トヨタが公開 ホンダも「通行実績情報マップ」
-
6
熊本で非常時Wi-Fi「00000JAPAN」発動中 KDDIが無料開放、他社ユーザーも利用可
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
「痺れるほどにミスを繰り返す」Gemini 3.6 Flashは変わった? 公開から1週間、当初のおバカ回答を今検証する
-
9
Anthropicのミュトス、暗号アルゴリズムの新たな攻撃法を発見――耐量子署名「HAWK」の強度を半減
-
10
“脳のゴミ”は鼻から捨てられていた? 老化で詰まる排出路、薬を鼻から投与で改善 韓国主導チーム研究
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR