リコー、低コスト・高速うたう新LLM 日英中対応で今秋提供
リコーは8月21日、日英中3言語に対応した、700億パラメータの大規模言語モデル(LLM)を開発したと発表した。米Metaが提供するLLM「Meta-Llama-3-70B」の日本語性能を高めた「Llama-3-Swallow-70B」をベースに、独自データによる追加学習などを実施。これにより、ベースモデルに比べ日本語の処理効率を43%向上させ、コスト効率や処理速度を高めたという。
 リコーのロゴ
リコーのロゴ
今回のLLMは、米Amazon Web Servicesと共同で開発したスクリプトで訓練した他、独自データ約1万6000件による追加学習を実施。テキストをLLMが理解できるよう分割する「トークナイザー」の改良により、日本語の処理効率を向上させた他、さらなる追加学習による「破滅的忘却」(追加学習の際に過去に学習したタスクを忘れる現象)も抑制したという。これにより、企業独自の「プライベートLLM」のベースとしても利用しやすいとうたっている。
複雑な指示・タスク処理の能力を評価する日本語のベンチマーク「ELYZA-tasks-100」では、回答速度で「Meta-Llama-3-70B-Instruct」「Llama-3-Swallow-70B-Instruct-v0.1」などのLLMを上回った。他のLLMのように、英語で回答してしまうこともなかったという。
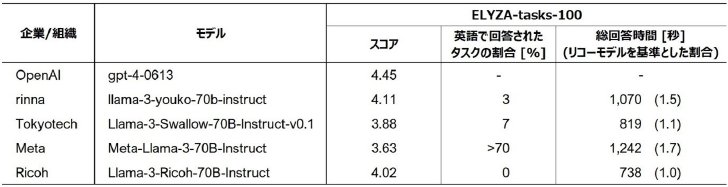 ベンチマークにおける比較結果
ベンチマークにおける比較結果
今回開発したLLMは、オンプレミス・クラウド双方の環境で利用できる形で、2024年秋に提供を始める。プライベートLLMとしての活用も視野に、まずは日本で提供し、その後海外への提供も目指す。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
Claude、利用制限を全リセット 競合「GPT-5.6」公開と同日……OpenAI幹部「ビビってるね」
-
3
「Claude Fable 5」サブスク、突如5日間延長 ユーザー悲喜こもごも「寝ずに頑張ったのに」「制限リセットして」
-
4
「まるで人間」 OpenAIの新モデル「GPT-Live」のトーク力が話題 間を空けずに考えながら会話できる
-
5
1万9000人が利用するソフトバンクの「全社RAG基盤」 構築の泥臭い舞台裏
-
6
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
7
AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
-
8
FDEとリコーの新コンサルサービス、どこが違う? AXのパートナー選びを考察
-
9
「誰にも会わずに帰る店」の寂しさ すかいらーくがロボット配膳の先に挑むAI接客
-
10
「生成AIをもう手放せない人」が約6割 逆に“使わなくなったもの”1位は?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR