AIモデル「Llama 3.3 Swallow」、東京科学大などのチームが公開 日本語能力は「GPT-4oに迫る」
東京科学大学情報理工学院の岡崎研究室と横田研究室、産業技術総合研究所の研究チームは3月10日、大規模言語モデル(LLM)「Llama 3.3 Swallow」を開発したと発表した。米MetaのLLM「Llama 3.3」をベースに日本語の能力を強化したAIモデル。日本語理解・生成タスクでは、米OpenAIのLLM「GPT-4o」にも迫る性能を記録したとしている。

今回公開したAIモデルは2種で、ベースモデルの「Llama 3.3 Swallow 70B v0.4」と、指示学習済みの「Llama 3.3 Swallow 70B Instruct v0.4」。どちらもLlama 3.3ライセンスで、これに従いつつ、米GoogleのGemma利用規約の利用制限に抵触しない範囲(学習用合成データにGemma2を使っているため)で、研究や商用などで利用できる。
70Bベースモデルの日本語理解・生成性能については、GPTシリーズなどの他社モデルと比較したところ、平均スコア「0.629」を記録。これは、1位のGPT-4o「0.646」に次ぐ2位の成績であり、3位のQwen2.5-72B「0.623」を上回った。研究チームは「GPT-4oに迫る性能といえる」と説明している。
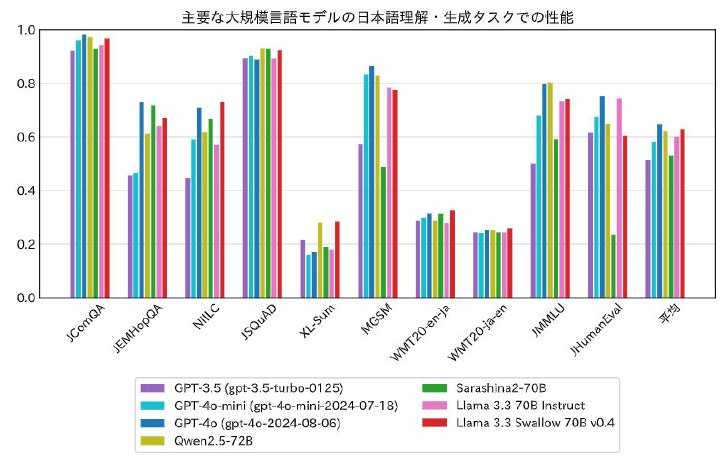 70Bベースモデルの日本語理解・生成性能比較
70Bベースモデルの日本語理解・生成性能比較
指示学習済みモデルの対話性能は、平均スコア「0.772」となり、GPT-4o(0.848)やQwen2.5-72B-Instruct(0.835)とは差がつく結果に。研究チームは「人文科学やライティングなど、知識や日本語に関するタスクは得意のようだが、コーディングや数学、推論などで差がついており、改善の余地がある」と述べている。
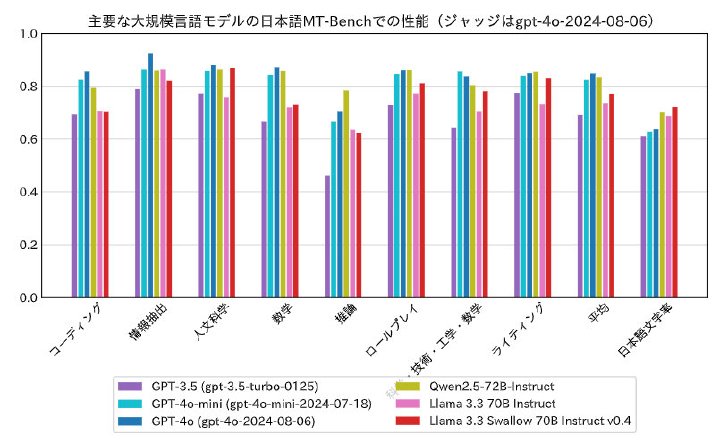 指示学習済みモデルの対話性能比較
指示学習済みモデルの対話性能比較
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
2
Z世代に聞く次の流行、「AIイラスト」が1位に 「Claude Code」も上位
-
3
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
-
4
MIXI、新卒エンジニア向け研修資料&動画を無料公開 「実践的なAI活用術」を12科目で紹介
-
5
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
6
スマホ映像から最短1分で高精細3Dモデル、NECが生成技術を開発
-
7
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
8
「iPhone高騰」はこれからも続く? 中国CXMTに近づくApple、メモリ競合へのけん制が不発に終わりそうなワケ【後編】
-
9
NVIDIA、Microsoft、OpenAIなどがオープンモデル規制反対を表明 Anthropic従業員は「CUDAのオープンソース化が楽しみ」と皮肉
-
10
ゼロから分かる「Claude」の教科書 ChatGPTと比べて分かった強みとは?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR