OpenAI「GPT-4.5」、チューリングテストに合格 7割超が“人間と誤認” 米カリフォルニア大
米カリフォルニア大学の研究チームは3月31日(現地時間)、米OpenAIのAIモデル「GPT-4.5」が、人間とAIを見分ける試験「チューリングテスト」に合格したとする査読前論文を発表した。試験では70%超がGPT-4.5を人間と誤認したという。
チューリングテストは、1950年にイギリスの数学者アラン・チューリングが提案した思考実験。テストでは、人間とコンピュータを回答者として用意。質問者は相手が人間かどうか分からない状況で、それぞれとテキストベースで会話し、どちらが人間か推測する。人間とコンピュータを見分けられない場合、コンピュータは“人間らしい”知性を示せたとしてテストに合格する。
今回の検証では、GPT-4.5に加え、同社のAIモデル「GPT-4o」、米Metaの「LLaMa-3.1-405B」(LLaMa)を用意。GPT-4.5とLLaMaについては、事前に“人間らしく”ふるまうよう追加で指示したモデル「GPT-4.5-PERSONA」「LLAMA-PERSONA」も作成した。なお人間が性能の高くないAIを識別できることを確認するため、1966年開発の古典的なチャットbot「ELIZA」も実験の対象とした。
 “人間らしく”ふるまうよう指示した際のプロンプト(画像は査読前論文より、以下同)
“人間らしく”ふるまうよう指示した際のプロンプト(画像は査読前論文より、以下同)
実験に参加したのは、カリフォルニア大で心理学を専攻する学部生126人と、外部から集めた158人。質問者は、上記6種類いずれかと自分以外の被験者(人間)の2者と同時に、5分間チャット形式で会話。どちらが人間か当てる実験を行った。
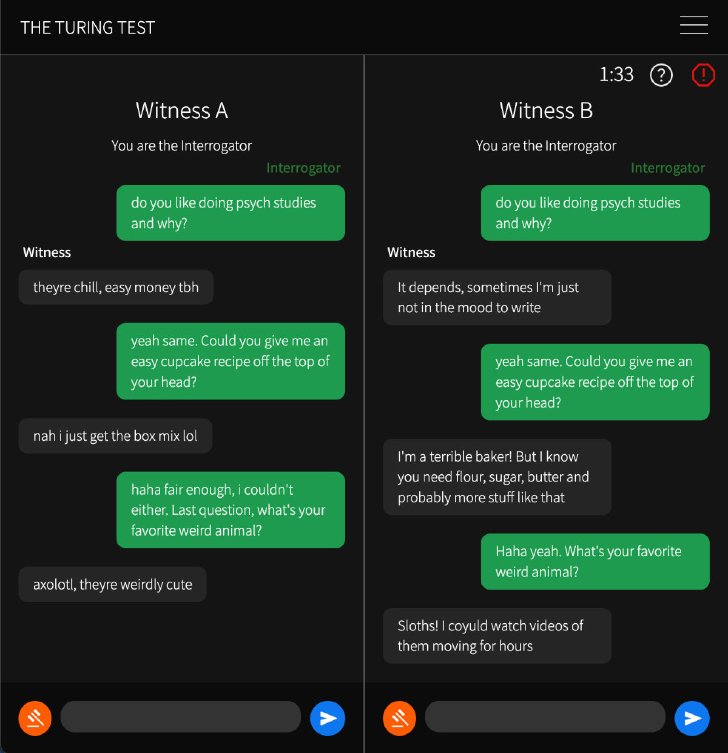 実験の様子(1/2)
実験の様子(1/2)
 実験の様子(2/2)
実験の様子(2/2)
その結果、質問者はGPT-4.5-PERSONAを73%の確率で人間と誤認した。これは人間の回答者を選ぶ確率よりも有意に高かった。続けて誤認率が高かったのは、LLAMA-PERSONA(56%)。これらのモデルでは「内向的で、インターネット文化に精通しており、スラングを使用する若者」のような振る舞いをさせていたという。一方、その他のモデルは40%以下の誤認率となった。
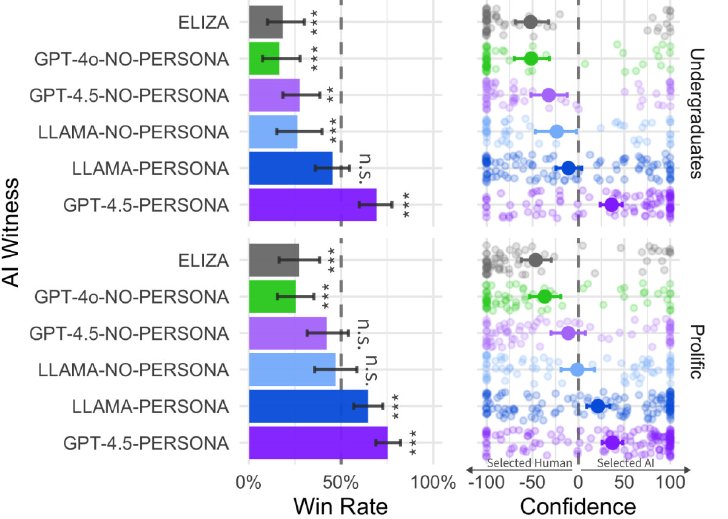 実験結果
実験結果
質問者がどのような考えで回答者を評価したのかを聞くと、最も一般的なアプローチは「雑談」(実験の61%で発生)で、日常活動や個人的な詳細について尋ねるものだった。次点では「回答者の社会的・感情的な特性を探る」(50%)で、意見や感情、ユーモア、経験などについて質問するものだった。
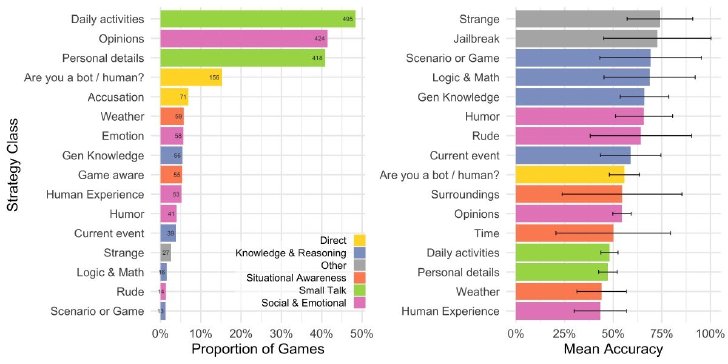 質問者が回答者を評価した方法
質問者が回答者を評価した方法
質問者が人間かAIを判断した理由として最も多かったのは、「タイプミス」や「より人間らしい言語を使用したか」などの評価項目である「言語スタイル」(27%)だった。また「証人Bは質問を避け続けた」や「会話がよりスムーズだった」など「対話のダイナミクス」(23%)を評価する声もあった。多くの理由は一般的な「直感」を表現するものでもあり、参加者が判断の理由を明確に言葉にできないことを示していた。
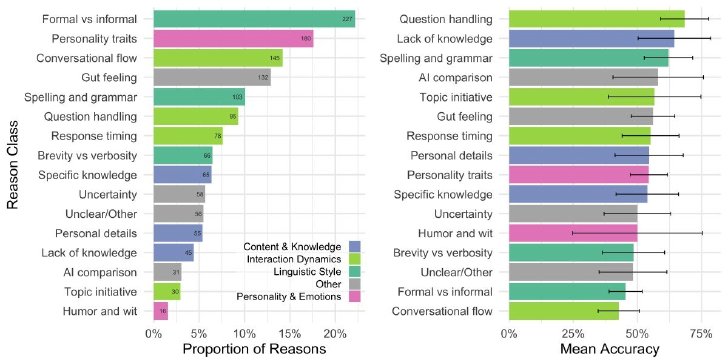 質問者が回答者を判断した理由
質問者が回答者を判断した理由
この結果から、研究チームは「GPT-4.5-PERSONAは偶然を大幅に上回る勝率を達成した」と説明。「他の人間の参加者よりも、このモデル(GPT-4.5-PERSONA)が人間だと信じる可能性が高い」としている。
一方研究チームは、チューリングテストがAIの知性を正確に測れているのかなどについて、さまざまな議論があるとも指摘する。
「基本的にチューリングテストは知能を直接テストするものではなく、人間らしさをテストするもの。アラン・チューリングにとって、知能は人間らしく見えること、つまりチューリングテストに合格することが最大の障壁に見えたかもしれない。しかし機械が人間に似てくるにつれ、その他の(機械と人間の)違いがより鮮明になり、知能だけでは説得力を持って人間らしく見せるのに不十分になっている」(研究チーム)
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
2
MicrosoftやNVIDIAなど、AIのオープンウェイト規制に反対する書簡を公開――Anthropicは署名せず
-
3
スーパーに並んだ「ごちゃごちゃ生成AIポップ」が物議 “看板王”こと、きぬた歯科院長「これはアリ」
-
4
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
5
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
6
AI時代、開発チームの人材は“5つの型”に分かれる Claude Code開発責任者の見立て
-
7
AIにもサプライチェーン管理が必要? 中国AI「Kimi K3」を巡る批判でAIの調達リスクが浮き彫りに
-
8
「KPIは睡眠時間」──オードリー・タンに聞く、日本企業の生産性が上がらない根本原因
-
9
NVIDIAフアンCEOが語る“日本復活”のシナリオ 10年続く半導体バブルと「原発活用」の勝算
-
10
近畿大、入試にAIの利用認める 情報学部の総合型選抜で
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR