Innovative Tech(AI+)
LLMの開発効率化に革新? 中国DeepSeekが「DeepSeek-OCR」発表 “テキストを画像化”でデータ圧縮
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
中国のDeepSeek-AIに所属する研究者らが発表した論文「DeepSeek-OCR: Contexts Optical Compression」は、本や画像などをスキャンして書いてある文字をデジタルテキストデータに変換するOCR(光学文字認識)を用い、長文を画像に圧縮する技術を発表した研究報告だ。
 中国DeepSeek、OCRを用いて長文を画像に圧縮する技術を発表
中国DeepSeek、OCRを用いて長文を画像に圧縮する技術を発表
大規模言語モデル(LLM)が長文を処理する際、文章の長さに応じて計算量が二次関数的に増大するという根本的な課題がある。DeepSeek-OCRは、文書を画像として扱い、視覚トークンへと変換することで大幅なデータ圧縮を実現している。
実験では、600~1300トークンを含む文書100ページ分で検証を実施。圧縮率が10倍以内であれば約97%という高い精度でテキストを復元でき、20倍という極端な圧縮でも約60%の精度を維持できることを実証した。これは「一枚の画像は千の言葉に値する」という概念を、技術的に具現化したものといえる。
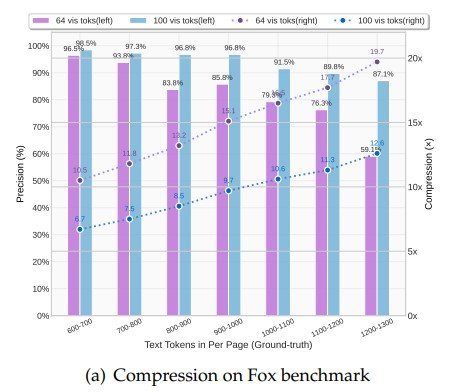 DeepSeek-OCRがFoxベンチマークで10-20倍の圧縮率で60~97%の精度を示した図
DeepSeek-OCRがFoxベンチマークで10-20倍の圧縮率で60~97%の精度を示した図
システムは、「DeepEncoder」と「DeepSeek-3B-MoE decoder」という2つの主要コンポーネントで構成。DeepEncoderは約3億8000万のパラメータを持ち、文書画像を効率的に圧縮する。DeepSeek-3B-MoE decoderは5億7000万の活性化パラメータを持ち、圧縮データから元の文章を復元する。
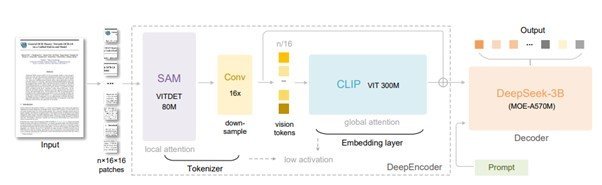 DeepSeek-OCRのアーキテクチャ
DeepSeek-OCRのアーキテクチャ
さらに、単純な文字認識だけでなく、文書内のグラフや図表、化学式、幾何学図形なども理解し、構造化されたデータとして出力できる。約100の言語に対応しており、アラビア語や少数言語の文書も処理可能だ。
 物体検出、画像の詳細説明、多言語文字認識など、汎用的な視覚理解タスクに対応できることを示す例
物体検出、画像の詳細説明、多言語文字認識など、汎用的な視覚理解タスクに対応できることを示す例
 DeepSeek-OCRが、数学文書内の幾何学図形を認識・解析し、テキストと図形の両方を構造化データとして抽出できることを実証している例
DeepSeek-OCRが、数学文書内の幾何学図形を認識・解析し、テキストと図形の両方を構造化データとして抽出できることを実証している例
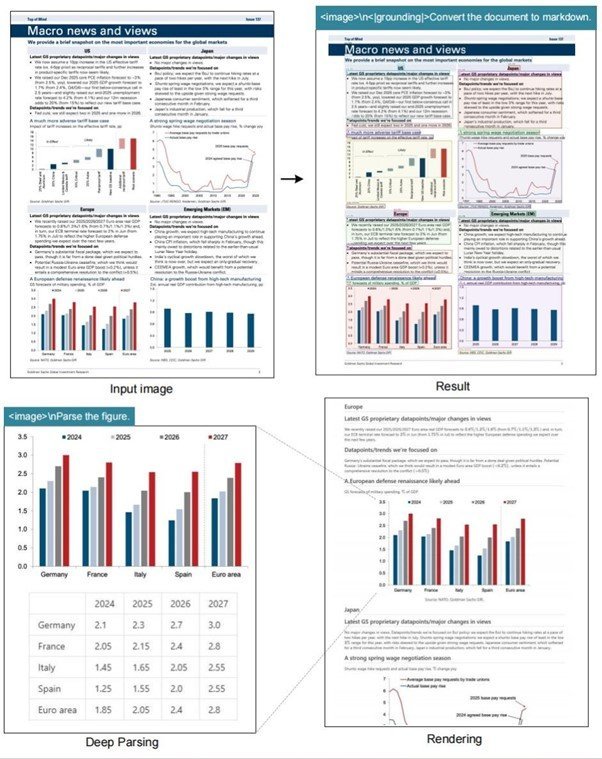 金融レポートや統計文書内のグラフ・表を自動検出し、構造化データとして抽出している例
金融レポートや統計文書内のグラフ・表を自動検出し、構造化データとして抽出している例
 書籍内の写真を詳細なキャプションとして言語化し、ページ全体のテキストと画像を統合的に出力している例
書籍内の写真を詳細なキャプションとして言語化し、ページ全体のテキストと画像を統合的に出力している例
実用性を高めるため、DeepEncoderは複数の解像度モードをサポートしている。最小のTinyモード(512×512、64トークン)から、最大のGundam-masterモード(1024×1024ローカルビュー、1280×1280グローバルビュー)まで、文書の種類や必要な精度に応じて選択可能だ。
ベンチマーク評価では優れた実用性を示している。PDF文書の解析に関する評価指標「OmniDocBench」において、わずか100視覚トークンで、OCRモデル「GOT-OCR2.0」(256トークン使用)を上回り、800トークン未満ではOCRモデル「MinerU2.0」(約6000トークン使用)を超えた。
生産環境では、1台のA100-40G GPUで1日当たり20万ページ以上の規模でLLM/VLM用の訓練データを生成できる処理能力を持つ。
なぜこの技術が重要なのか。現在のLLMは、長い文章を扱うときに計算コストが急激に増大するという問題を抱えている。DeepSeek-OCRのアプローチは、この問題に対する新しい解決策を提示している。文字を文字として扱うのではなく、画像として扱うことで、処理効率を向上させることができる。
Source and Image Credits: Haoran Wei, Yaofeng Sun, Yukun Li. DeepSeek-OCR: Contexts Optical Compression
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Claude、利用制限を全リセット 競合「GPT-5.6」公開と同日……OpenAI幹部「ビビってるね」
-
2
「まるで人間」 OpenAIの新モデル「GPT-Live」のトーク力が話題 間を空けずに考えながら会話できる
-
3
auが生成AI「Stable Diffusion」でリメイクしたお正月CMを放映
-
4
テスラ車内で「Grok」と会話、日本でも展開へ ナビ設定やルート確認を音声で
-
5
デスクトップ版ChatGPT大幅刷新 AIエージェント「Codex」統合、「ChatGPT Work」に
-
6
「生成AIをもう手放せない人」が約6割 逆に“使わなくなったもの”1位は?
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
「誰にも会わずに帰る店」の寂しさ すかいらーくがロボット配膳の先に挑むAI接客
-
9
「Claude Fable 5」サブスク、突如5日間延長 ユーザー悲喜こもごも「寝ずに頑張ったのに」「制限リセットして」
-
10
CEOの利用額も「全社員に丸見え」 LayerXがAI予算を「第二の人件費」にした真意
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR