OpenAIの「オープンなAI(gpt-oss-120b)」はGPUサーバじゃないと動かない?→約30万円の自作PCで動かしてみた
これまで「クローズドなAI」を提供してきた米OpenAIが、8月5日(現地時間)についに「オープンなAI」を公開した。「gpt-oss-120b」と「gpt-oss-20b」の2種類で、前者はGPUサーバに搭載されるようなグラフィックスカード「NVIDIA H100」1枚で、後者はハイエンドなデスクトップ・ノートPCで動作するとしている。いずれも無料でダウンロードできる。
H100は80GBのビデオメモリ(VRAM)を持つ一方、家庭向けのグラフィックスカードはハイエンドな「NVIDIA GeForce RTX 5090」でもVRAM 32GBと、H100に比べれば少ない。LLMの実行にはそのパラメータ(120bや20bの部分。bは10億の意味)をメモリに展開しなければならず、gpt-oss-120bは約66GBのメモリを必要とすることから「普通に実行するならH100が必要」というわけだ。
しかし、H100は単体で約500万円。一般人がおいそれと購入できる額ではない。そこで、一般家庭で組める自作PCでgpt-oss-120bを実行してみた。
マシン構成
マシンの構成は以下。
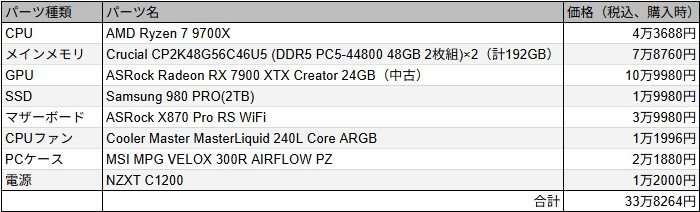 マシン構成のパーツ一覧
マシン構成のパーツ一覧
 マシンの実機。光る機能は不要ではあるものの、あったらあったで案外楽しい気持ちになったりもする
マシンの実機。光る機能は不要ではあるものの、あったらあったで案外楽しい気持ちになったりもする
これらのパーツを組み立てることにより、全体としてはメインメモリ(RAM)192GB+VRAM 24GB、合わせて216GBのメモリを活用できる自作PCとなっている。
今回選んだグラフィックスカードは、ハイエンドにもかかわらずPCIeの排気スロットを2スロットしか占有しないスリムなモデル。多くのハイエンドグラフィックスカードは約3スロットを占有するのでマザーボードに1枚しか差せない(もしくはライザーケーブルを使って特殊なレイアウトにしないと2枚目を差せない)のだが、2スロット占有モデルであれば特殊レイアウトではなくとも2枚目を差せる余裕がある、というのが選定理由だ。
 ASRock Radeon RX 7900 XTX Creator 24GBはハイエンド機としては珍しい2スロット占有モデル
ASRock Radeon RX 7900 XTX Creator 24GBはハイエンド機としては珍しい2スロット占有モデル
 メインメモリは48GB×4の192GB。なお、パーツの相性などの関係でメモリクロックは多少下げて(4200MT/s)の運用となっている。2枚96GB運用にすれば本来の5600MT/s以上で動作する可能性はある
メインメモリは48GB×4の192GB。なお、パーツの相性などの関係でメモリクロックは多少下げて(4200MT/s)の運用となっている。2枚96GB運用にすれば本来の5600MT/s以上で動作する可能性はある
「でも結局VRAMが24GBしかないのならメモリ66GBが必要なgpt-oss-120bは動かないのでは? それにNVIDIAではなくAMDのGPUでそもそも動くのか?」という疑問もあるかもしれない。
これらについては、LLMをさまざまな計算資源で実行できるように開発された「llama.cpp」というライブラリが解決しており、llama.cppを採用した「LM Studio」や「Ollama」などのLLM実行ソフトウェアを使うことで、NVIDIAのGPUがなくてもAMDのGPU(とVRAM)+CPU(とRAM)のような組み合わせでLLMを動作させることが可能になっているのだ。しかも、AI用途などからNVIDIAのGPUはコンシューマ向けでも高騰しているのに対し、AMDのGPUはかなり落ち着いた価格となっている。NVIDIAのCUDA環境でゴリゴリAIの学習をしたいということでなく、あくまで推論が目的ならAMDのGPUは現状かなり良い選択肢だ。
より詳しいPCスペックの説明は別の機会に譲るが、もう一つだけ重要なポイントは、マザーボードのチップセットX870はPCIeレーンのx8+x8分割に対応している、つまりGPUとマザー側との転送帯域を均等に分配できるので、GPUの2枚差した際に片方がボトルネックになってしまうということがないということだ。古いマザーボードではPCIeスロットが2つあっても下のスロットはx1など狭い帯域しか設定できない場合もあるので、もしGPU2枚差しを考えているなら気を付けたいポイントだ(正直筆者もこの辺りは超詳しいわけではないので識者の皆さまの指摘求む)。
20bモデルは爆速!
各モデルの実行環境についてはOpenAIがさまざまな方法を案内しているが、今回は筆者が慣れているLM Studioで実行。まずは小型の20bをダウンロードしてみる。
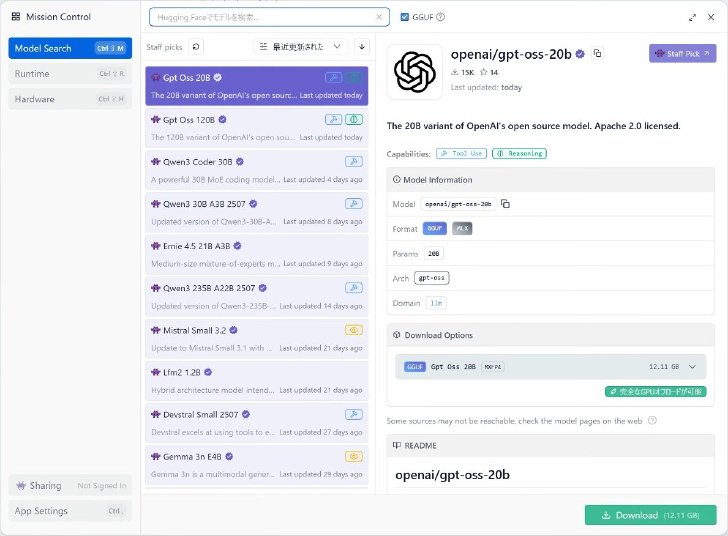
ファイルサイズは約12GB。GPUのVRAMに載り切るサイズだ。
実行するにはLM Studioの「読み込むモデルを選択」というボタンから詳細を設定。「GPUオフロード」という項目で24/24とすれば基本はOKだ。これは「ニューラルネットワークレイヤー24層のうち24層ともGPUで計算しますよ」という意味。
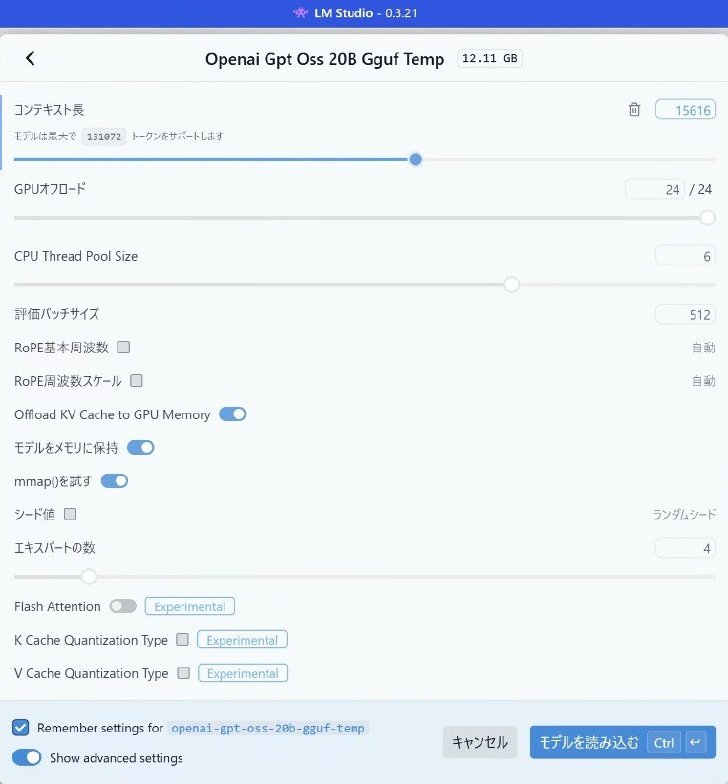 20bモデルの読み込み設定。コンテキスト長は1万5616トークンまでの制約があるようだった
20bモデルの読み込み設定。コンテキスト長は1万5616トークンまでの制約があるようだった
もう一つの大事な設定項目は「コンテキスト長」で、これによりどれくらいの文章を入出力できるかが決まる。デフォルトでは4096トークンとなっており、最大で13万1072トークンまでサポート可能とあるが、筆者が試した限りでは1万5616トークンまでしか設定できず、1万5617トークンにするとエラーとなりモデルを読み込めなかった。
1万5616トークンで読み込んでもVRAMの占有量は13.5GBで、まだまだ余裕がある。1万5616は256×61に因数分解できることも考えると、モデル側の何らかの制約である可能性もありそうだ(ちなみに同様の問題は120bでも発見した)。
追記:2025年8月6日午後5時20分 コンテキスト長の制限は推論環境のせい?
サポート可能な最大コンテキスト長まで設定できない問題については、モデル側ではなく非NVIDIAの推論環境(おそらくはllama.cpp)に問題がありそうだ。NVIDIA GeForce RTX 4090(VRAM 24GB)を搭載している別のマシンで試したところ、1万5616トークンを超えて設定できることが分かった。
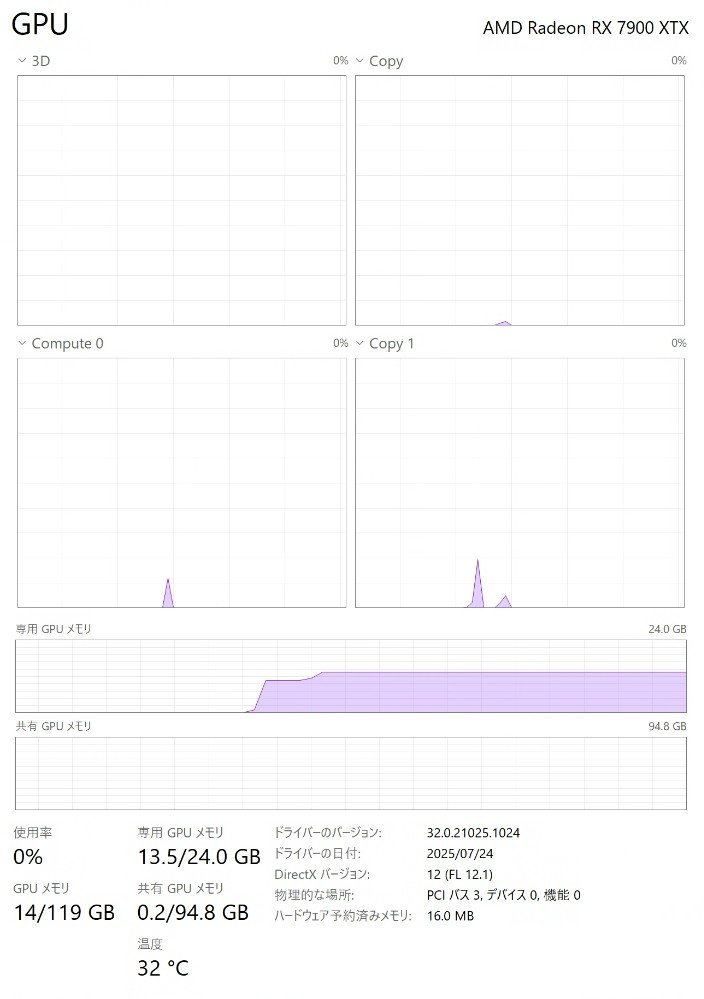 上記設定で20bを読み込んだ際のGPUのメモリ消費量は約14GB。VRAM 16GBのグラフィックスカードでも大丈夫なはずだ
上記設定で20bを読み込んだ際のGPUのメモリ消費量は約14GB。VRAM 16GBのグラフィックスカードでも大丈夫なはずだ
20bは数学が得意ということなので、簡単な微分方程式を解かせてみた。
回答は正しく、それが約140tokens/sで出てくるのはかなり驚異的といえるのではないだろうか。ちなみに、少し前までAIが間違いやすい問題として有名だった「9.9と9.11はどちらが大きい?」という問題も難なくクリアする。
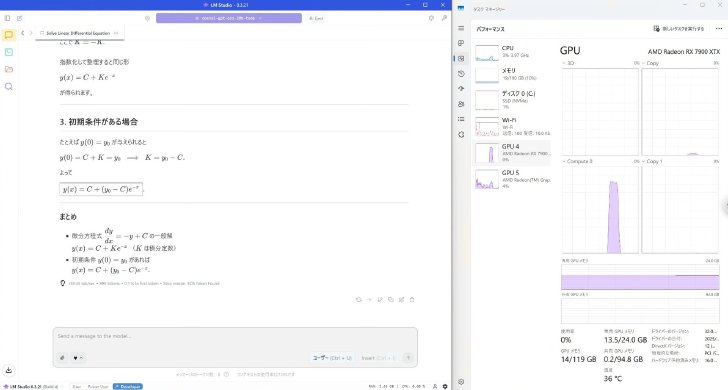 計算中のGPU使用率は約80%。CPUへの負担はあまりない。約140tokens/sという圧倒的な速度で回答が出力される
計算中のGPU使用率は約80%。CPUへの負担はあまりない。約140tokens/sという圧倒的な速度で回答が出力される
120bは動くか?
小型な20bはしっかり動くことが分かったところで、大型な120bはどうだろうか。ファイルサイズは約64GBあり、ダウンロードだけでも筆者の環境では40分ほどかかってしまった。
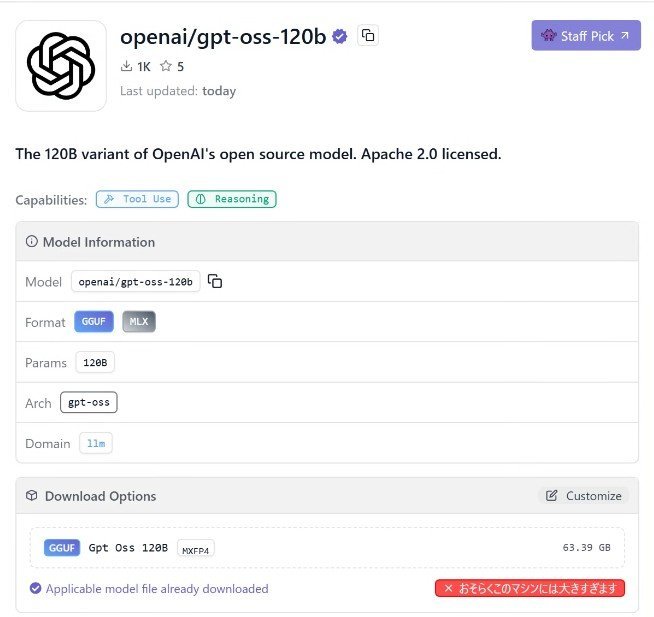
また、筆者が試した時間帯ではまだLM StudioのGUIからはダウンロードができず、コマンドラインを使ってダウンロードする必要があったが、現在(日本時間午前6時30分)ではGUIからダウンロードできるようになっている。
こちらもダウンロードが終われば、読み込み方は20bの手順と同じ。筆者と同じ環境であれば、GPUオフロードは14層までにしておくのがVRAMにぴったり収まる設定になる。設定上は全36層をオフロードしても動作はするのだが、VRAMの24GBからあふれた分は共有GPUメモリという名のメインメモリに結局配置される上、GPUが回る割にはCPU・メインメモリとの通信がボトルネックになり、ただGPUが発熱するだけという結果になることが分かったので筆者はおすすめしない(というか無意味だと思う)。
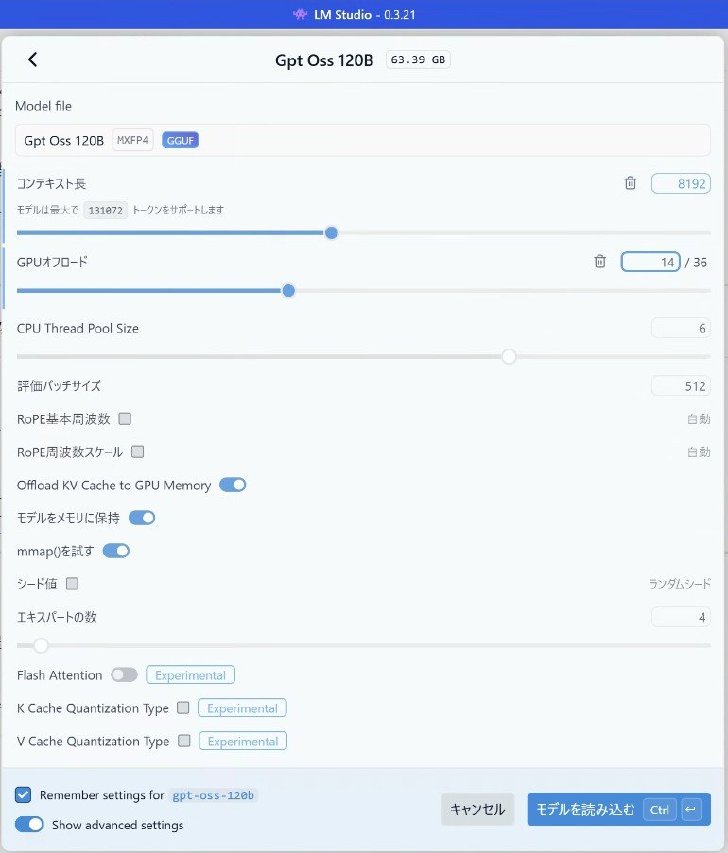 gpt-oss-120bの読み込み設定。ちなみにFlash Attentionなどのメモリ削減オプションは機能しなかった
gpt-oss-120bの読み込み設定。ちなみにFlash Attentionなどのメモリ削減オプションは機能しなかった
コンテキスト長も20bと同じく何らかの理由で制限があり、設定できる最大サイズは8192トークンだった。これも256×32に因数分解できるので、制限の理由は20bと同じかもしれない。
さて、では20bと同じ問題を解かせてみよう(ここでは推論の性能差ではなくあくまで速度のみを見ることにする)。GPU使用率は約30%、CPU使用率は約60%で推移。回答は正しく、推論速度は約8.4tokens/sだった。
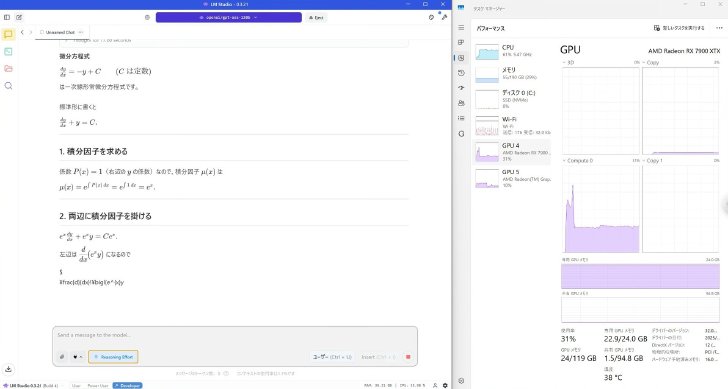 120bモデルの推論中のGPU・CPU使用率
120bモデルの推論中のGPU・CPU使用率
 推論結果。速度は約8.4tokens/sだった。120bモデルは「Reasoning effort」という設定項目があり、どれくらい推論を頑張らせるかをユーザー側で設定できる
推論結果。速度は約8.4tokens/sだった。120bモデルは「Reasoning effort」という設定項目があり、どれくらい推論を頑張らせるかをユーザー側で設定できる
約8.4tokens/sという速度は20bの140tokens/sに比べれば断然に遅いものの、人間が文章を読む速度とあまり変わらない(数式のような考える必要がある文ならなおさらだ)。
LM StudioやOllamaといったLLM実行ソフトウェアで読み込んだモデルは、「Cline」や「Roo Code」といったAIコーディングエージェントの推論エンジンにすることもできるが、約8.4tokens/sをAIコーディングエージェントに用いるとおそらくは日が暮れてしまうだろう。AIコーディングエージェントの実行にはコンテキスト長も求められることから、現状最大8192トークンというのも厳しい。
この実行環境としては、AIコーディングエージェントに使うよりは完全ローカルなAIアシスタントチャットとして使う方が向いていそうだ。
自作PCでgpt-oss-120bは動く! 動くが他の選択肢もある
いずれにせよ「H100でなくても約30万円の自作PCでgpt-oss-120bは動く!」ということは明らかになった。
ちなみに、MacのユーザーによればM2 Ultraの環境で約70tokens/sは出るようだ。
また、さまざまなLLMを単一のAPIで実行できるプラットフォーム「OpenRouter」では、プロバイダにもよるが入力0.15ドル/100万トークン、出力0.6ドル/100万トークンでgpt-oss-120bを利用できる。つまり100万トークン使っても1ドルもかからない。
簡単に試すだけなら、OpenAIがgpt-oss-120bを公式に公開しているHuggingFaceのページからも無料で試すこともできる。
よって、用途としてはこんな分け方になるだろう。
- とりあえず無料で触ってみたい→HuggingFaceへ
- ローカルで実行する必要はない→OpenRouter(やそのルーティング先の推論プロバイダ)へ
- 完全ローカルで実行したい
- 高額でも推論速度は速い方がいい→Apple Silicon Macのハイメモリモデルへ(NVIDIAのDGX SparkやAMDのRyzen AI Max+ 395搭載機も近いことができるはずだが未知数)
- とにかく安く動く環境を作って後から拡張したい→自作PCへ
こう見比べてみると、自作PCで動かそうという筆者は偏屈な選択をしているなあと思う部分もないわけではない。いずれにしても、最近のオープンなモデルとしては中国のDeepSeekやAlibabaのQwen 3シリーズが存在感を放っていたので、米GoogleのGemmaシリーズだけでなく、OpenAIからもオープンなモデルが出てきたのは、ユーザーの選択肢としては喜ばしいことではないだろうか。
更新履歴
2025年8月6日午後5時20分 コンテキスト長の制限について追記
著者:井上輝一
ITmedia NEWS、ITmedia AI+編集長。2016年にITmedia入社。AIやコンピューティング技術、科学関連を取材。2022年からITmedia NEWS編集長に就任。2024年3月に立ち上げたAI専門メディア「ITmedia AI+」の創刊編集長。ITmedia主催イベントで多数登壇の他、テレビや雑誌へも出演歴あり。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
2
Z世代に聞く次の流行、「AIイラスト」が1位に 「Claude Code」も上位
-
3
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
「iPhone高騰」はこれからも続く? 中国CXMTに近づくApple、メモリ競合へのけん制が不発に終わりそうなワケ【後編】
-
6
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
7
スマホ映像から最短1分で高精細3Dモデル、NECが生成技術を開発
-
8
MIXI、新卒エンジニア向け研修資料&動画を無料公開 「実践的なAI活用術」を12科目で紹介
-
9
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
10
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR