Copilot+ PCやハイスペックマシンでお手軽ローカルLLM「LM Studio」を試してみた UIがかなり使いやすいぞ DeepSeekの小型モデルも動く
さまざまな話題を巻き起こしている中国の「DeepSeek-R1」だが、その驚きの一つはモデルの公開、そしてその中にはハイスペックなデスクトップPCやノートPCでも工夫次第で実行できる小型なモデルも含まれていたことだった。
LLMのハイエンドはビッグテック企業がサービスやAPI越しに提供している超巨大モデルではあるものの、ローカルで実行できるサイズのLLMにも実はいろいろな変化が起こりつつある。
そんな変化を手軽に実感できるアプリとして今回紹介したいのが「LM Studio」だ。
 LLMをPCでお手軽に実行できる「LM Studio」(撮影:井上輝一、以下同様)
LLMをPCでお手軽に実行できる「LM Studio」(撮影:井上輝一、以下同様)
モデルダウンロードから実行までGUIで完結する「LM Studio」
LM Studioは米Element Labsが開発しているローカルLLMのフロントエンドアプリだ。対応OSはMac、Windows、Linuxと幅広い。特にWindows版ではx64の他にARMもサポートしているため、Snapdragon X Elite/Plusを搭載したCopilot+ PCでも利用できる。ここでは、Snapdragon X Eliteを搭載した「Surface Pro」でLM Studioを試してみる。
 Snapdragon X Eliteを搭載した「Surface Pro」でLM Studioを試してみた
Snapdragon X Eliteを搭載した「Surface Pro」でLM Studioを試してみた
LM Studioのインストールは、公式サイトトップページの「Download LM Studio for Windows(arm64)」をクリックしてインストーラーをダウンロード。ちなみにARM版はARM機からサイトにアクセスした場合にしか表示されない。
 LM Studio公式Webサイトのトップページ(引用元:Element Labs)
LM Studio公式Webサイトのトップページ(引用元:Element Labs)
インストーラーを起動して、いくつかボタンをポチポチすればインストールは完了。特に悩むことはないはずだ。
インストールが完了してLM Studioを開くと、ウェルカムスクリーンとともに最初のLLMとして「Llama 3.2 1B」(1Bは10億パラメータの意)をダウンロードするかどうかを尋ねられる。スキップもできるが、非常に軽量(約1.3GB)なため実用性はともかくとして動作確認のためにダウンロードしておこう。
メインのウィンドウは、2025年1月30日時点で最新版であるバージョン0.3.8においては左端に画面の切り替えボタン(上からチャット画面、デベロッパー画面、DL済みのモデル一覧画面、モデルなどの検索画面)が並び、画面下端にはバージョン情報やシステムリソースの利用状況、設定ボタンが並んでいる。デフォルトの表示言語は英語だが、設定画面で日本語に変更できる。日本語の方が親しみやすい人は日本語に変更しておこう。
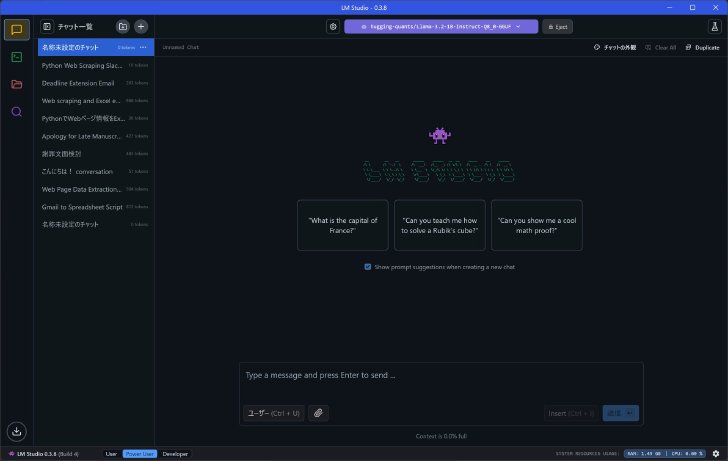 LM StudioのUI
LM StudioのUI
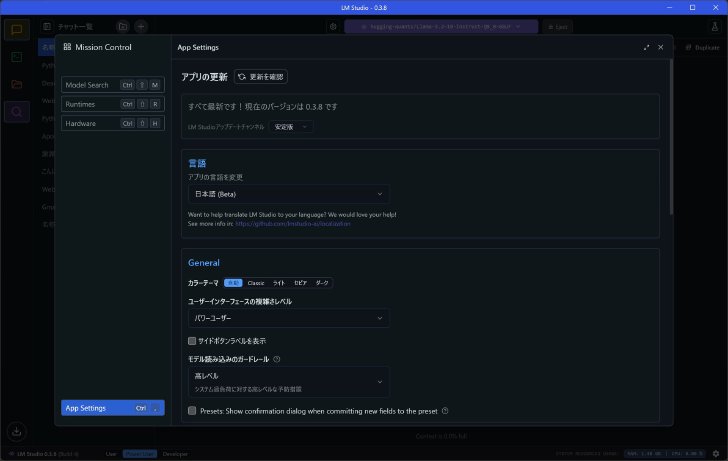 右下の歯車ボタンから設定に入り、表示言語を変えられる
右下の歯車ボタンから設定に入り、表示言語を変えられる
チャット画面に戻り、まずはLlama 3.2 1Bを使ってみよう。自分がいまどのLLMをロードしているかは、チャット画面中央上に表示されている。ここをクリックすればLLMを切り替えられる。
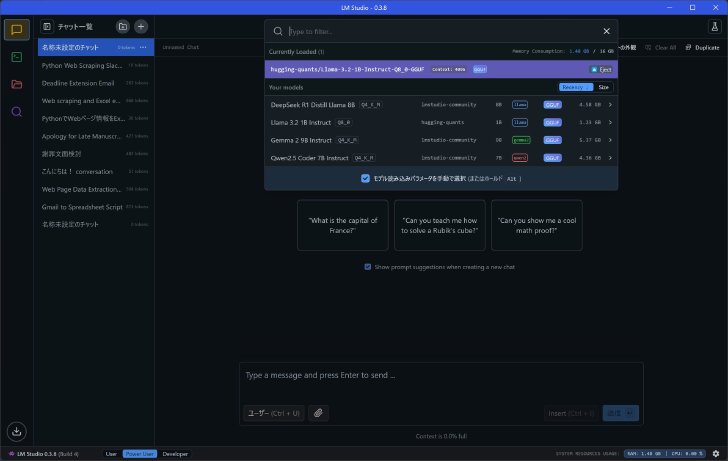 チャット画面中央上からダウンロード済みのLLMを切り替えられる
チャット画面中央上からダウンロード済みのLLMを切り替えられる
Llama 3.2 1Bをロードした状態で入力エリアに「こんにちは!」などを入れて送信。なんらかの応答が返ってくれば、ひとまず動作確認はOKだ。
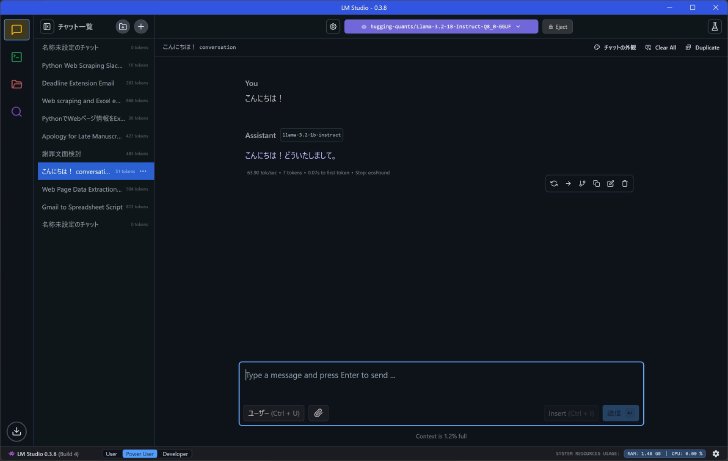 「Llama 3.2 1B」に「こんにちは!」と送ってみると「こんにちは!どういたしまして。」と返ってきた。とりあえず動作確認はOK
「Llama 3.2 1B」に「こんにちは!」と送ってみると「こんにちは!どういたしまして。」と返ってきた。とりあえず動作確認はOK
では、もう少し性能の高いLLMを使ってみよう。
HuggingFaceからよりどりみどり メモリ16GBなら動くのはおよそ9Bまで
他のLLMを探すには、左端の虫眼鏡マークボタンから検索画面を開く。すると、デフォルトではLM StudioのスタッフがピックアップしたLLMが30個ほどリストされているのが確認できるはずだ。主なところでは、米MetaのLlamaシリーズ、米GoogleのGemmaシリーズ、米MicrosoftのPhiシリーズ、中国DeepSeekのDeepSeek R1 Distillシリーズ、中国AlibabaのQwenシリーズなど。
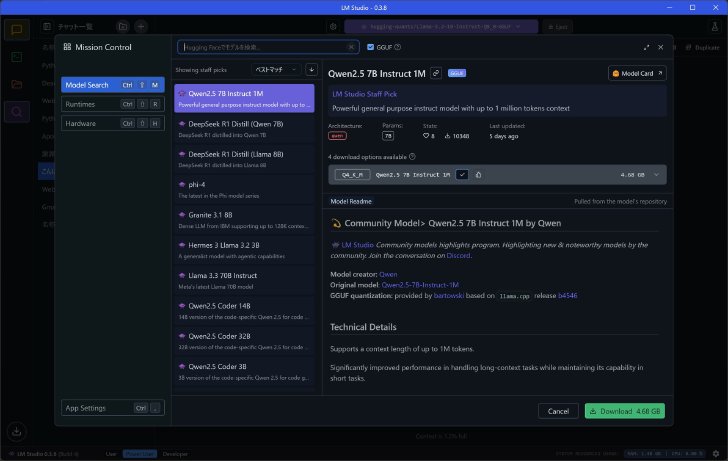 検索画面からデフォルトで見られるLLMのラインアップ。検索窓からさらに詳しく検索も可能
検索画面からデフォルトで見られるLLMのラインアップ。検索窓からさらに詳しく検索も可能
それぞれクリックしてみると右画面に詳細が表示される。この詳細画面を見てピンと来る人もいると思うが、接続先は「HuggingFace」というLLMやAIモデルを共有・公開できるWebサイトになっている。HuggingFace上で各モデルの概要を説明する「モデルカード」が、LM Studio上でも表示されているということだ。
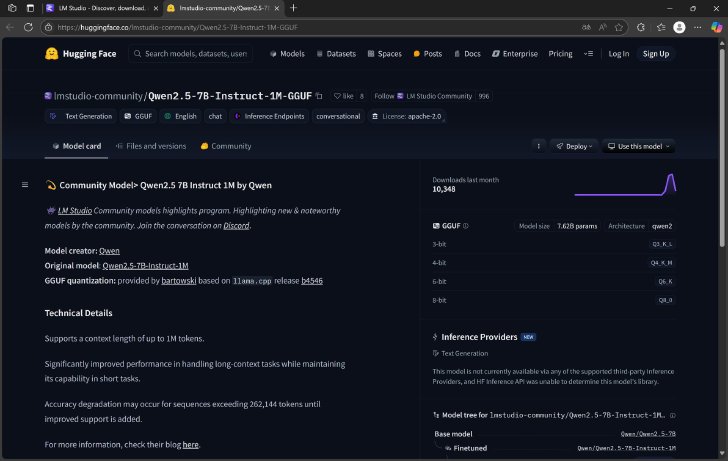 検索画面右側で表示されているのはHuggingFace上のモデルカード(引用元:HuggingFace)
検索画面右側で表示されているのはHuggingFace上のモデルカード(引用元:HuggingFace)
試しに、「DeepSeek R1 Distill(Llama 8B)」を見てみよう。詳細画面を見ると、「4 download options available」などと書かれた項目がある。ここを開いてみるといくつかファイルサイズの異なるモデルが選べるようになっているはずだ。
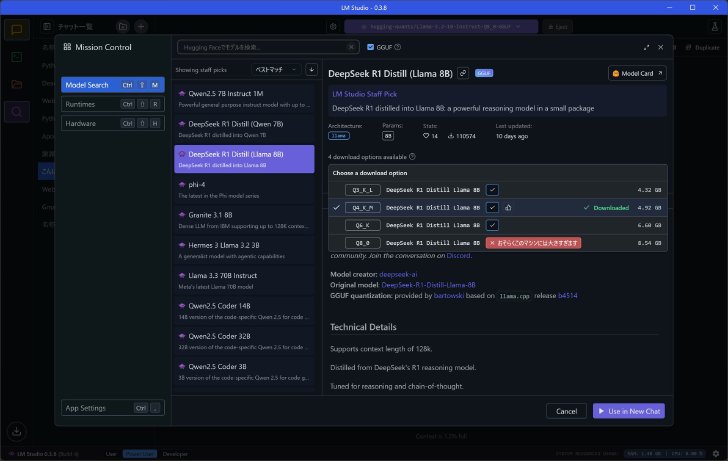 1つのLLMに対して複数のオプションが提供されている場合がある
1つのLLMに対して複数のオプションが提供されている場合がある
モデルそれぞれには「Q3」「Q4」といったラベルが付けられてる。これは「何ビットで量子化したか」という意味で、Q4なら4ビット量子化ということ。量子化はモデルの精度を下げてファイルサイズ(メモリにロードすべき容量)を減らす手法。元のモデルは32ビットや16ビットを1つのパラメータに割り当てているのでそれだけ細かな表現ができるのだが、そのビット数を下げると、精度の低いおおざっぱな表現になってしまうがその分だけファイルサイズを下げられる、ということになる。
DeepSeek R1 Distill(Llama 8B)の場合、Q3、Q4、Q6、Q8の4モデルが並んでいる。ありがたいのが、実行しているマシンのハードウェアからどのモデルが適しているか、あるいはこのモデルは大きすぎてこのマシンではロードできない、ということを教えてくれることだ。今回試しているSurface Proはメモリ16GBとなるが、DeepSeek R1 Distill(Llama 8B)の場合であればQ4が推奨され、Q8は大きすぎておそらく無理と表示される。
他のモデルも観察してみると、例えば14BのモデルはQ2でも大きすぎ。Gemma 2 9BならQ4が推奨モデルでQ6は大きすぎ、といった具合だったので、メモリが16GBの場合はこのあたりが上限になってくるだろう(外部GPUがある場合はこの限りではない)。
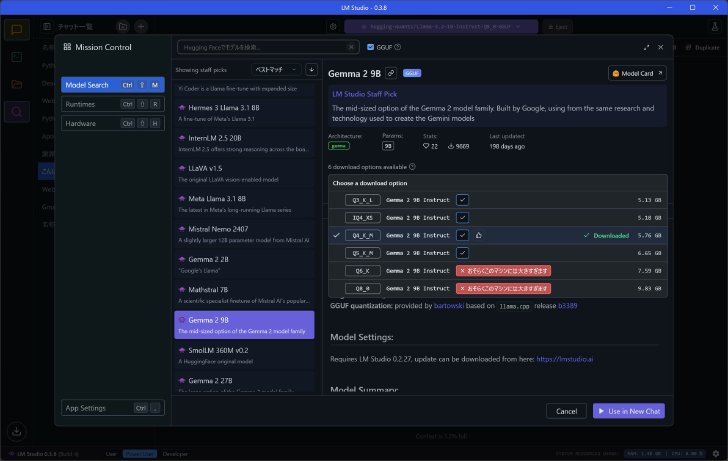 Gemma 2 9Bもメモリ16GBで実行可能だが、大きくても5ビット量子化モデルまでのようだ
Gemma 2 9Bもメモリ16GBで実行可能だが、大きくても5ビット量子化モデルまでのようだ
DeepSeek R1 Distill(Llama 8B)のQ4モデルを選び、右下のダウンロードボタンをクリック。ダウンロードボタンにはファイルサイズも「4.92GB」と表示されている。クリックするとダウンロードの進捗を示すウィンドウが開かれ、これまでダウンロードしたモデルや現在ダウンロード中の状況、通信速度や残り時間などが分かる。
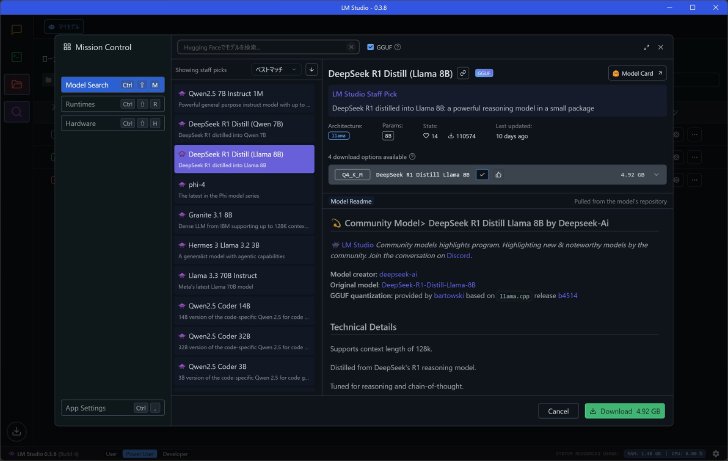 推奨マークのついているQ4モデルを選び、右下のダウンロードボタンをクリック
推奨マークのついているQ4モデルを選び、右下のダウンロードボタンをクリック
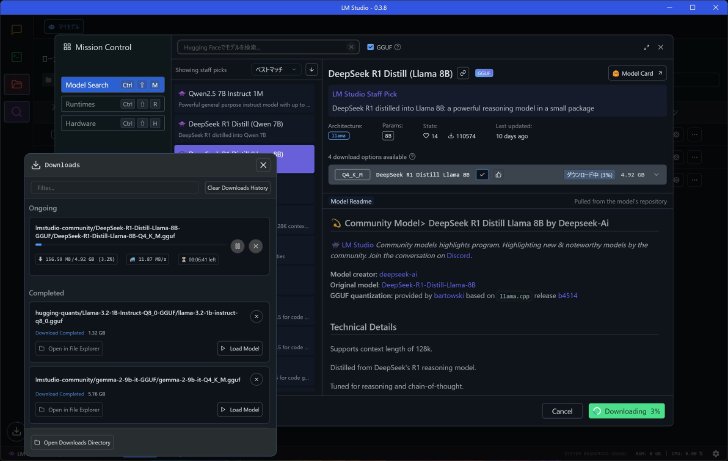 ダウンロードの進捗状況も分かる
ダウンロードの進捗状況も分かる
ちなみに、これはLM Studioの問題かWindowsの問題か、あるいはSnapdragonの問題か、はたまたHuggingFaceの問題かよく分かっていないのだが、モデルの詳細やダウンロードをクリックしても通信が始まらずエラーになることがある。こうしたときはアプリを再起動したり、しばらく時間を置いたりするとだいたい直る。原因は不明。
DeepSeek R1 Distill(Llama 8B)とご対面 どれくらい賢い?
ダウンロードが終わると、右下に完了の旨と「Load Model」というボタンが表示される。ここをクリックすればモデルを読み込んでチャット画面に遷移。チャットを始められる。
「締め切りが過ぎてしまった原稿を編集に送りたい。メールの謝罪文面を考えてほしい。文面は日本語で書いて」という文を送ってみる。返ってきた回答が以下画像。
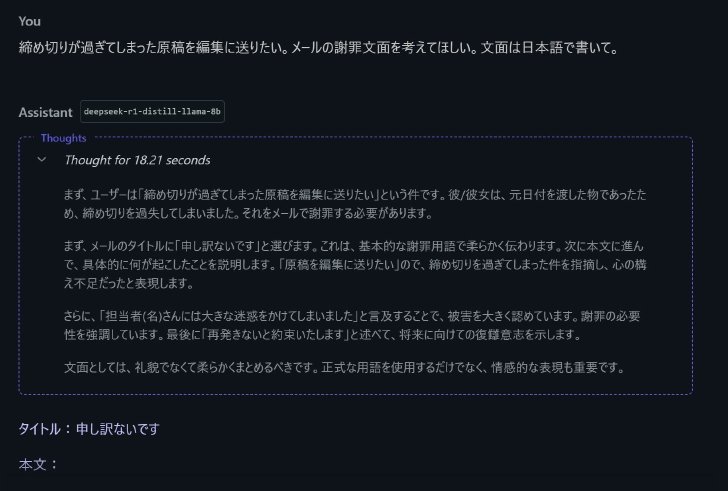 DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
 (続き)DeepSeek R1 Distill(Llama 8B)による回答
(続き)DeepSeek R1 Distill(Llama 8B)による回答
どうもあまり賢い文章とは言えない。もともと英語と中国語をメインに訓練されているモデルなので日本語的な表現は難しいのかもしれない。
では英語で送ってみよう。回答は以下。
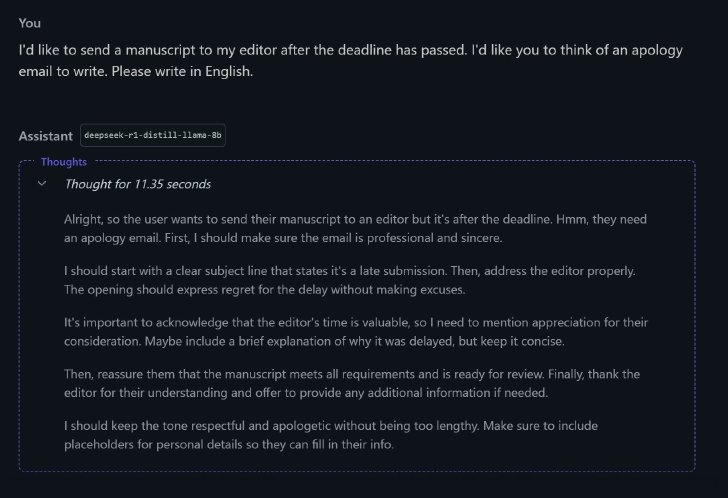 DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
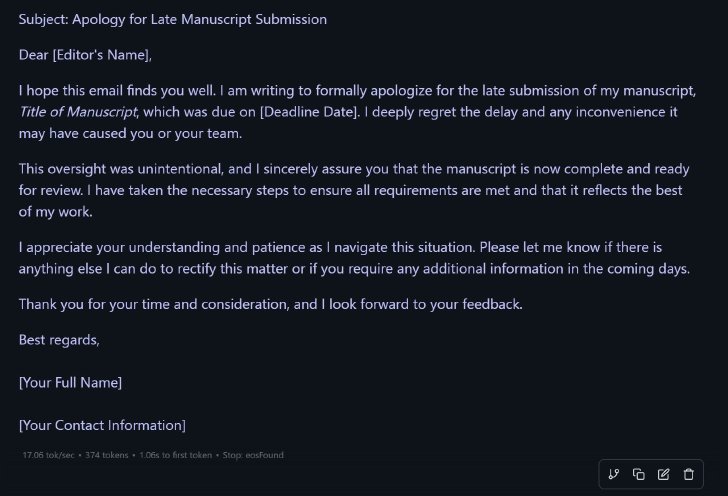 (続き)DeepSeek R1 Distill(Llama 8B)による回答
(続き)DeepSeek R1 Distill(Llama 8B)による回答
英語の方がまだまともな文章に見える(ネイティブから見ればダメ出しの点はあるだろうが)。17token/sec、つまり英語であれば1秒当たり17単語で出力できているので、表示速度としては及第点ではないだろうか。
プログラミングはどうだろう。「PythonでWebページ(example.com)を開き、ページタイトルとURLをExcelに保存するコードを書いて」と送ってみる。
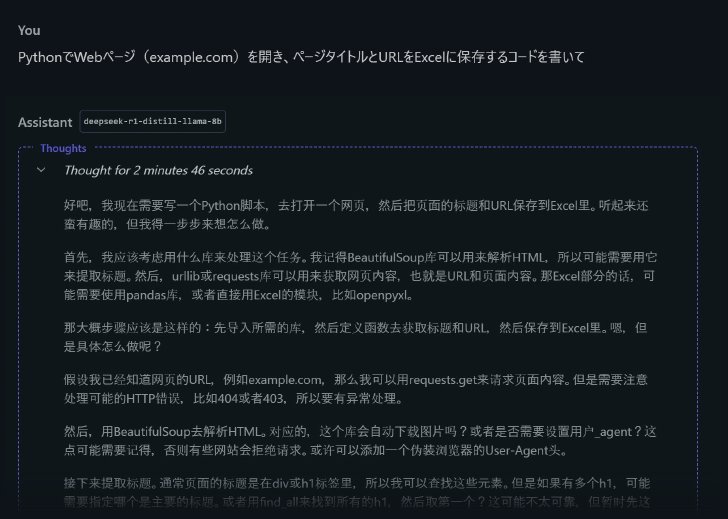 DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
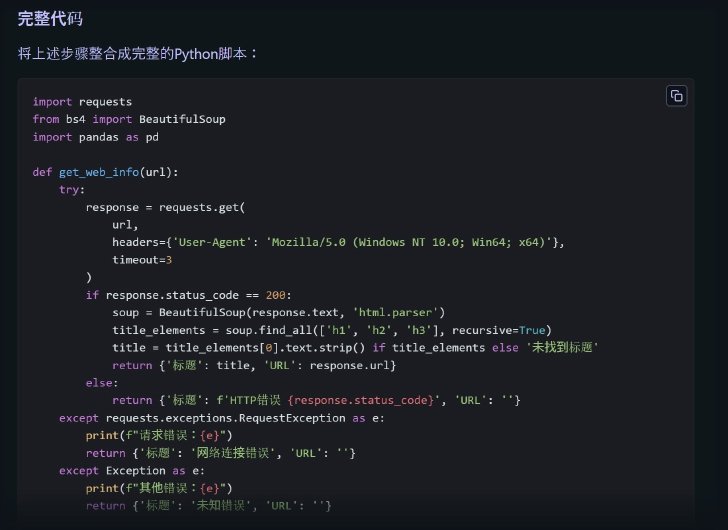 (続き)DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
(続き)DeepSeek R1 Distill(Llama 8B)による回答(次に続く)
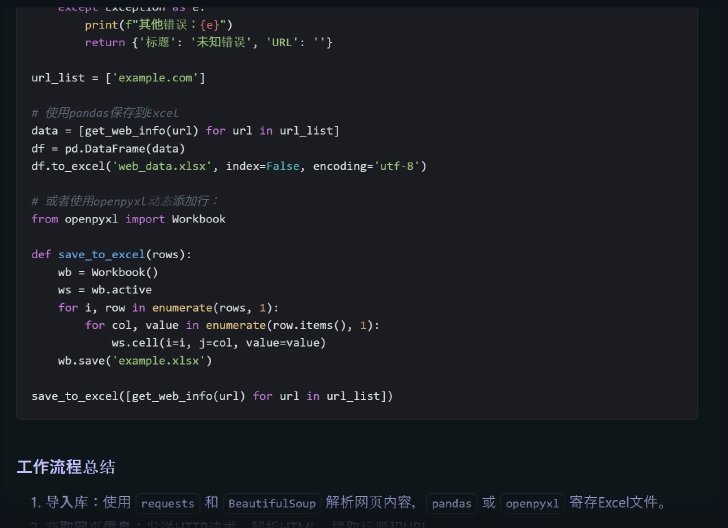 (続き)DeepSeek R1 Distill(Llama 8B)による回答
(続き)DeepSeek R1 Distill(Llama 8B)による回答
2分半の思考の結果、中国語でのレスポンスが返ってきた。importしているモジュールは悪くなさそうだが、実行してみるとどうだろうか。
URLがドメインのみになっていたのでhttps://を付け足した上で実行したが、エラーに。df.to_excel()という関数の引数が間違っているようなので直して実行。余計な関数でエラーは発生したものの、Excelファイルを保存することはできた。
ちなみに、コーディングに特化した「Qwen2.5-Coder-7B-Instruct」をロードして同じ指示をしてみたところ、ほぼ一瞬でコードを生成。コメントも日本語だ。初めの応答ではopenpyxlが使われてないコードだったので、使うよう指示し直して出てきたコードは特にエラーもなく完了した。
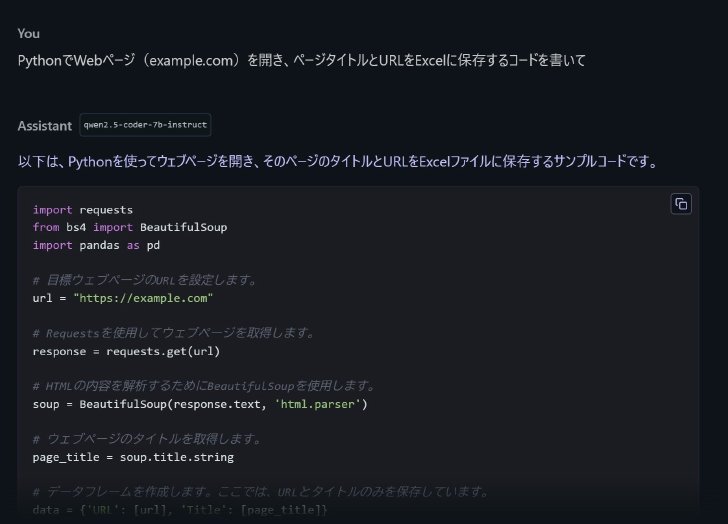 Qwen2.5-Coder-7B-Instructによる回答(次に続く)
Qwen2.5-Coder-7B-Instructによる回答(次に続く)
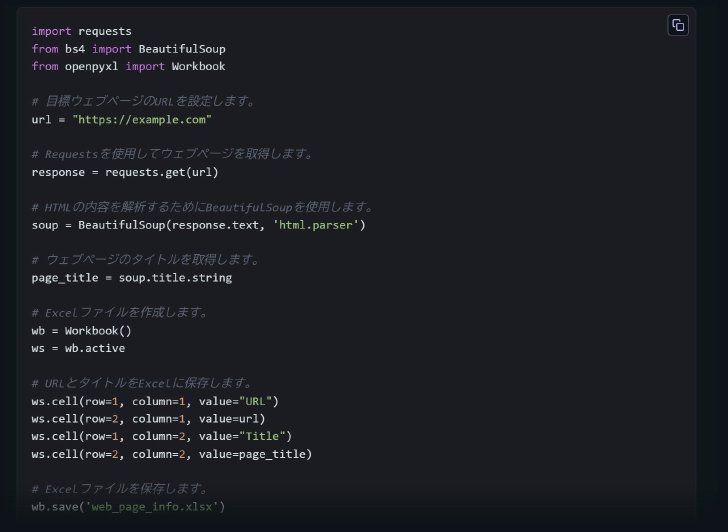 (続き)Qwen2.5-Coder-7B-Instructによる回答(次に続く)
(続き)Qwen2.5-Coder-7B-Instructによる回答(次に続く)
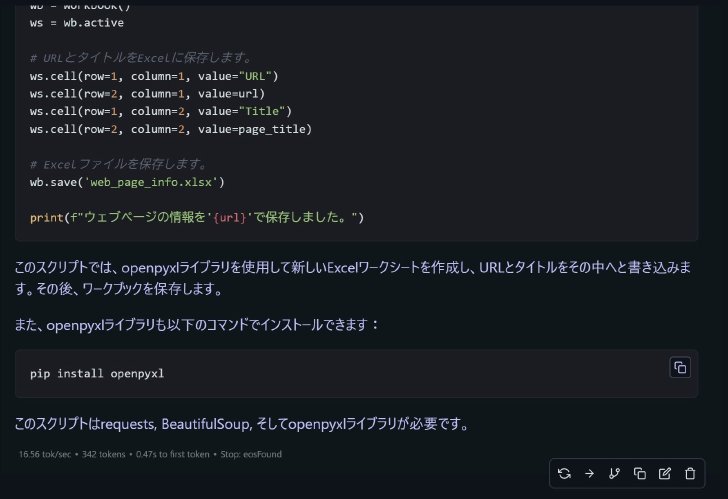 (続き)Qwen2.5-Coder-7B-Instructによる回答
(続き)Qwen2.5-Coder-7B-Instructによる回答
先ほどの謝罪メールも、実は「Gemma 2 9B」に実行させた方が日本語として破綻しておらず、それなりの文章が返ってくる。
 Gemma 2 9Bによる回答
Gemma 2 9Bによる回答
各タスクに向いたLLMを選んで使いこなすのが小型モデルのポイント
これらから言えるのは「小型なDeepSeek R1のモデルの性能は必ずしもいいとは言えないこと」と、「モデルごとに向いたタスクがある」ということだ。Qwen2.5-Coder-7B-Instructはその名の通りコーディングに特化しているし、gemma-2-9bに関してはLLMのベンチマークサイトである「Chatbot Arena」の日本語性能ランキングで同じくGoogleが開発している「Gemini-Exp-1206」がトップとなっている他、gemma-2-9bも悪くない順位に入っていることを筆者は事前に知っていた。
こうしてさまざまなLLMを手元で試せるようになってきたのは、PCのスペックとLLMの小型化技術の双方が進展してきた結果といえる。ローカルでの実行であれば外部に情報を送る心配がないため、少なくとも情報漏えいの観点は安全だ。
一点気を付けてほしいのは、それぞれのLLMにはライセンスがあり、ものによっては利用シーンが制限されているものもある。各LLMを利用する際はライセンスもあわせて確認してほしい。
実機として今回はSnapdragon X Elite搭載のSurface Proを利用した。CPU性能が高いためそれなりのトークン生成速度が出ているが、実はSnapdragon X Eliteの売りであるAI専用プロセッサ「NPU」での実行はできていない。これはLM StudioがSnapdragonのNPUに未対応なためだ(AMD RyzenのNPUは実験的に対応している)。LM Studioではないが、DeepSeek-R1の蒸留モデルを各NPUで実行できるようにチューニングしたものをMicrosoftが順次公開していくと発表もあった。NPU実行に対応すれば、より省電力かつ速い生成速度が期待できるだろう。
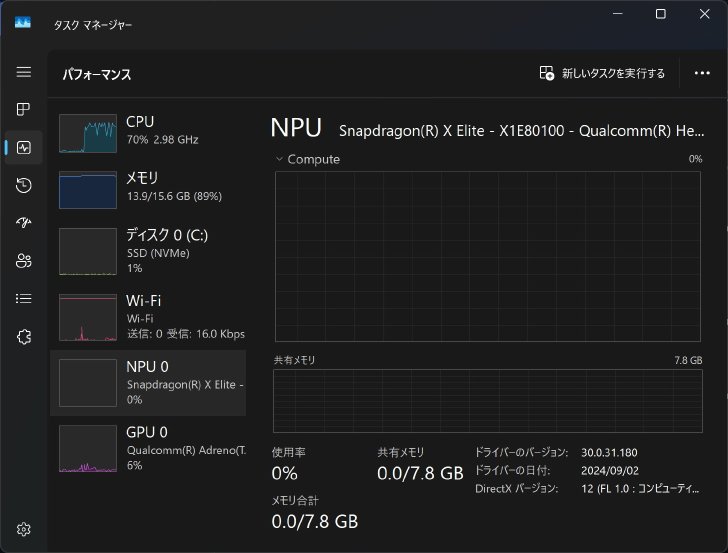 LLM実行中のタスクマネージャーの様子。メモリがほぼ使い切られ、CPU使用率も70%まで回っているがNPUは動いていない
LLM実行中のタスクマネージャーの様子。メモリがほぼ使い切られ、CPU使用率も70%まで回っているがNPUは動いていない
もちろん、NVIDIAのGPUがあれば、GPUのVRAM容量に応じてより大きなLLMを運用することもできる。コンシューマ向けハイエンドグラフィックスカードである「GeForce RTX 4090」(VRAM24GB)を搭載したマシンで筆者が確認した限りでは、DeepSeek-R1-Distill 32Bの4ビット量子化モデルならVRAMにギリギリ搭載可能だ。1月30日に販売が始まった「GeForce RTX 5090」はVRAMが32GBとさらに拡張されているので、より大きなモデルも選択肢に入るかもしれない。また、LM StudioはApple Silicon Macにも対応しているので、Macでメモリを盛るのも一つの手だ。
いずれにしても、LLMを安全に実行できる環境はすでにある。そのためのPCのスペックを改めて見直してもよさそうだ。
著者:井上輝一
ITmedia NEWS、ITmedia AI+編集長。2016年にITmedia入社。AIやコンピューティング技術、科学関連を取材。2022年からITmedia NEWS編集長に就任。2024年3月に立ち上げたAI専門メディア「ITmedia AI+」の創刊編集長。ITmedia主催イベントで多数登壇の他、テレビや雑誌へも出演歴あり。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
千代田区、Copilot全庁導入で月2000時間削減 10カ月でAIを根付かせた定着の仕掛け
-
2
AI・半導体企業トップが語る“稼ぎ頭” キオクシア、フジクラ、東京エレデバの見解まとめ【無料PDF】
-
3
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
4
Claude、一部チャットがGoogle検索で“丸見え”に 過去には「ChatGPT」でも 漏えいの原因は?
-
5
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
6
地震、台風、有事の寸断――日本のサプライチェーン危機管理を変えるとき
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
-
9
マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
-
10
「Claudeより4割安い」 M365のExcel/メール操作を丸投げる「Copilot Cowork」“従量課金”の落とし穴
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR