第2のDeepSeekショック? オープンな中国LLM「Qwen3」シリーズが破格の性能で話題 最大モデルはOpenAI o1やGemini 2.5 Proに匹敵、たった4BでもGPT-4oレベルに
中国Alibabaが4月29日(現地時間)に発表した、大規模言語モデル「Qwen」の最新版となる「Qwen3」シリーズが話題だ。フラッグシップモデルの「Qwen3-235B-A22B」は「DeepSeek-R1」の半分未満のパラメータ数ながら、OpenAIのo1やo3-mini、GoogleのGemini 2.5 Proなど他のトップモデルと並ぶ性能を達成したという。「Qwen3-4B」は小さなモデルでありながらも「GPT-4o」を多くの項目で上回るとしている。
 AlibabaによるQwen3の解説ページ(出典:Alibaba、以下同様)
AlibabaによるQwen3の解説ページ(出典:Alibaba、以下同様)
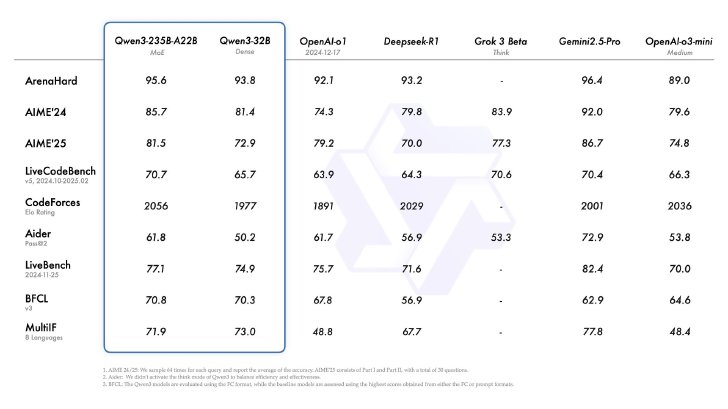 「Qwen3-235B-A22B」「Qwen3-32B」と他社トップモデルとの比較
「Qwen3-235B-A22B」「Qwen3-32B」と他社トップモデルとの比較
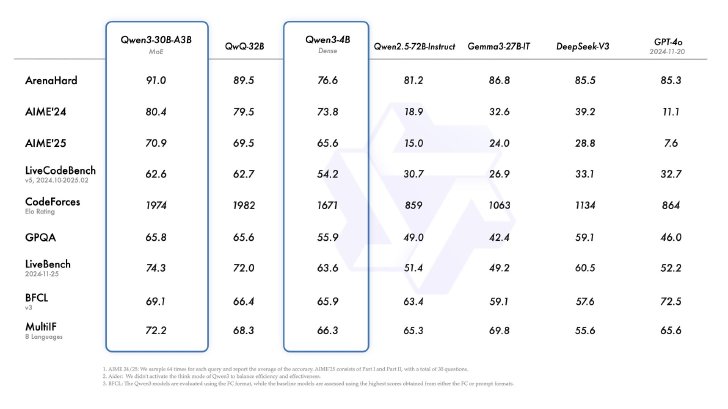 「Qwen3-30B-A3B」「Qwen3-4B」とGPT-4oなどとの比較
「Qwen3-30B-A3B」「Qwen3-4B」とGPT-4oなどとの比較
公開した全てのモデルがオープンウェイトであるため、フラグシップの235B-A22B以外はデスクトップ向けハイエンドGPUなどで動作させることもできる。
Qwen3シリーズの特徴は思考(Thinking)モードと非思考モードを切り替えられること。思考モードはOpenAI o1やDeepSeek R1で言う「Reasoning」や、Claude 3.7 Sonnetで言う「Thinking」のことで、モデルが段階的に推論を行うことで回答の精度を上げるモードのこと。タスクの複雑さに応じて使い分けられる。
MoEモデルとしては大型の「Qwen3-235B-A22B」と小型の「Qwen3-30B-A3B」の2つ、Denseモデルとしては「Qwen3-32B」「Qwen3-14B」「Qwen3-8B」「Qwen3-4B」「Qwen3-1.7B」「Qwen3-0.6B」の6つが、オープンウェイトかつApache 2.0ライセンスで公開された。
MoE(Mixture-of-Experts)は、専門家(Experts)と呼ばれる複数のサブニューラルネットワークを内部に持ち、実際に推論する際はそのうちの数個のみを活性化パラメータとして利用するモデル。対するDense(密)モデルはパラメータを全て利用して推論する従来的なモデル。MoEは計算コストを抑えながら性能を上げられる側面を持つ。
小型MoEモデルの「Qwen3-30B-A3B」も興味深い性能を示す。活性化パラメータが10倍ある同社の思考モデル「QwQ-32B」を上回る性能を発揮するという。活性化パラメータが小さい分、推論時の実行速度の向上が見込まれる。
Qwen3は119の言語と方言をサポートしており、日本語も含まれている。これにより、グローバルなアプリケーション開発が可能になり、世界中のユーザーがこのモデルの能力を活用できるようになるとしている。
Qwen3の事前学習には、Qwen2.5の18兆トークンに対し、約2倍の36兆トークンを使用した。このデータセットはWebサイトだけでなくPDF形式の文書からも収集され、Qwen2.5-VLを使用してテキストを抽出。Qwen2.5で品質を向上させたという。また、数学やコードのデータ量を増やすために、Qwen2.5-MathとQwen2.5-Coderを使用して合成データを生成した。
事前学習プロセスは3段階で構成されており、第1段階ではコンテキスト長4Kトークンで30兆以上のトークンを学習。第2段階ではSTEM、コーディング、推論タスクなどの知識集約型データの割合を増やし、最終段階では高品質な長文コンテキストデータを使用してコンテキスト長を32Kトークンに拡張している。
事後学習プロセスでは、長いCoT(思考連鎖)のコールドスタート、思考の強化学習、思考モードの融合、一般的な強化学習という4段階で235B-A22Bと32Bを作成。その結果を蒸留することで30B-A3Bやその他の小型Denseモデルを作成した。
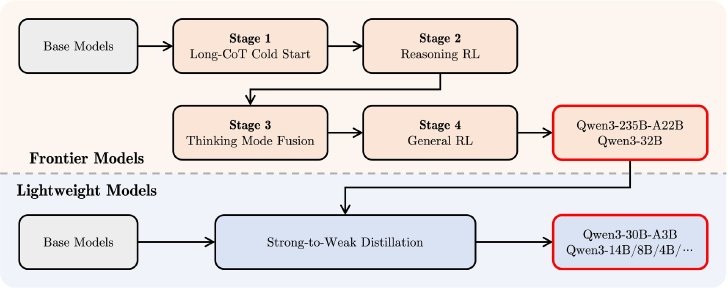 事後学習プロセスの流れ
事後学習プロセスの流れ
Qwen3モデルはHugging FaceやKaggleなどのプラットフォームで利用可能。ローカルでの使用には、Ollama、LMStudio、MLX、llama.cpp、KTransformersなどのツールが推奨されている。Alibabaが提供するWebアプリ「Qwen Chat」でも利用できる。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
2
MicrosoftやNVIDIAなど、AIのオープンウェイト規制に反対する書簡を公開――Anthropicは署名せず
-
3
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
4
スーパーに並んだ「ごちゃごちゃ生成AIポップ」が物議 “看板王”こと、きぬた歯科院長「これはアリ」
-
5
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
6
AI時代、開発チームの人材は“5つの型”に分かれる Claude Code開発責任者の見立て
-
7
NVIDIAフアンCEOが語る“日本復活”のシナリオ 10年続く半導体バブルと「原発活用」の勝算
-
8
「KPIは睡眠時間」──オードリー・タンに聞く、日本企業の生産性が上がらない根本原因
-
9
「生成AIで仕事が楽に」のはずが……IT現場を蝕む“AI疲れ・AIうつ”の正体
-
10
AIにもサプライチェーン管理が必要? 中国AI「Kimi K3」を巡る批判でAIの調達リスクが浮き彫りに
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR