Meta、動画内アイテム識別AI「SAM 3」と3Dモデル「SAM 3D」を公開
米Metaは11月19日(現地時間)、動画内のアイテムも識別できるAIモデル「Segment Anything Model 3」(SAM 3)を発表した。コードとモデルの重みを独自の「SAM License」の下、GitHubで公開した。このリリースには、SAM 3とともに、単一画像からの3D物体、人体再構築のためのオープンソースモデル群「SAM 3D」も含まれている。
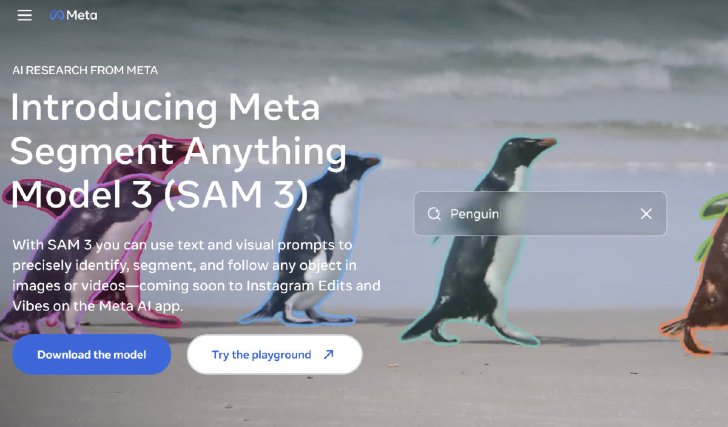
SAM 3は、画像と動画のプロンプト可能なセグメンテーションのための統一基盤モデル。テキスト、例示、ボックスやマスクなどの視覚的プロンプトを使ってオブジェクトを検出し、セグメント化し、追跡できるというものだ。
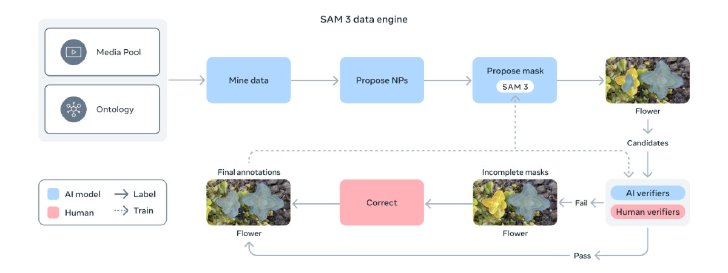 SAM 3のエンジン概要
SAM 3のエンジン概要
前身である「SAM 2」と比較して、短いテキストフレーズや例示で指定されたオープンボキャブラリーの概念のすべてのインスタンスを網羅的にセグメント化する能力を導入した点で進歩している。従来のモデルが「人」のような広範囲な概念をセグメント化するのに対し、SAM 3は「赤いストライプの傘」のような、より微妙な概念に対応できる。
このモデルは、既存のベンチマークよりも50倍以上多い27万のユニークな概念を含むという新ベンチマーク「SA-Co」で、人間のパフォーマンスの75~80%を達成し、既存システムに比べて2倍の性能向上を示したという。この進歩は、400万以上のユニークな概念を自動的にアノテーションしたデータエンジンによって支えられているという。
これらのモデルの応用として、SAM 3とSAM 3Dは、Facebook Marketplaceの新しい「View in Room」機能を強化しており、ユーザーが購入前に自宅の空間でランプやテーブルなどの家具類のスタイルやフィット感を視覚化できるようにしている。
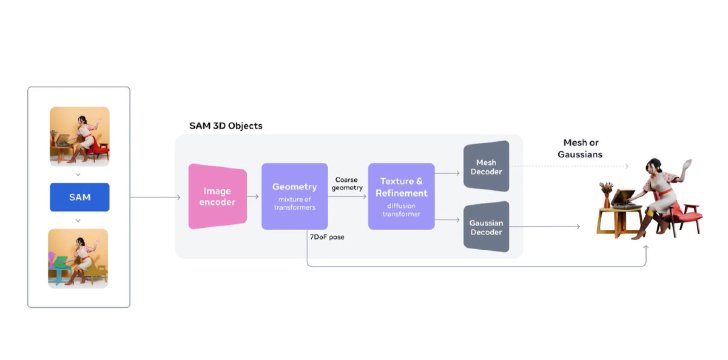 SAM 3が画像から3Dオブジェクトを生成するまでの処理工程
SAM 3が画像から3Dオブジェクトを生成するまでの処理工程
また、SAM 3は、Instagramの動画作成アプリ「Edits」に間もなく導入される新しいエフェクトを可能にし、クリエイターが動画内の特定の人やオブジェクトにダイナミックなエフェクトを適用できるようにする。
SAM 3は、マルチモーダルLLMのための知覚ツール「SAM 3 Agent」としても利用でき、「手を挙げていない座っている人」などのより複雑なテキストクエリをセグメント化することができる。科学分野では、野生生物モニタリング用の公開ビデオデータセット「SA-FARI」の構築に使用されている。これらのモデルの機能は、誰でも「Segment Anything Playground」で体験できる。
 Segment Anything Playground
Segment Anything Playground
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
【一時非公開のお知らせ】「バズるほど赤字だった」──野田クリスタルのAIペットカードゲーム、公開停止からの復活劇を本人に聞いた
-
2
コードなしでもベイズ統計ができる無料の神ツール「JASP」 ~ マウス操作だけでここまでできる
-
3
「Claude」利用制限を全リセット CodexとChatGPT Workも “リセット合戦”再び
-
4
フアンCEO「ジャパンAI構築はマストだ」 経産省、国産フィジカルAIで新プロジェクト 赤沢大臣も“革ジャン”羽織る
-
5
OpenAI、初のハードウェア「Codex Micro」を230ドルで発売 Apple提訴の渦中にある端末とは別物
-
6
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
7
大手共同出資の“国産AI開発企業”が本格始動 NVIDIAも協力、「Rubin」2万7500基搭載の計算基盤を構築へ
-
8
「AIと壁打ちはもう古い」 業務タスクを任せる「Claude Cowork」の落とし穴
-
9
「Gemini Spark」日本でもリリース、まずUltraから 24時間働く“パーソナルAIエージェント”
-
10
富士通、国内ロボット大手3社と「フィジカルAI」で協業 NVIDIAの技術活用
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR