プログラミング素人、ChatGPTで「YouTubeの字幕作成」自動化にトライ 動画制作を効率化できるか?(3/3 ページ)
ただ、同音異義語の間違いはどうしても発生する。ChatGPTによると「Whisper文字起こしの“最大の弱点”が同音異義語の誤変換」だという。また、用語の不統一や表記揺れなどもあり、このあたりは、別途校閲ツールを用意して修正するなどの作業が必要になる。
ここまでの作業で、一応は、字幕用のSRTファイルが完成した。ただし、誤変換の問題は、YouTube動画の管理ツール「YouTube Studio」の字幕編集機能で動画を再生しながら手直ししているのが現状だ。
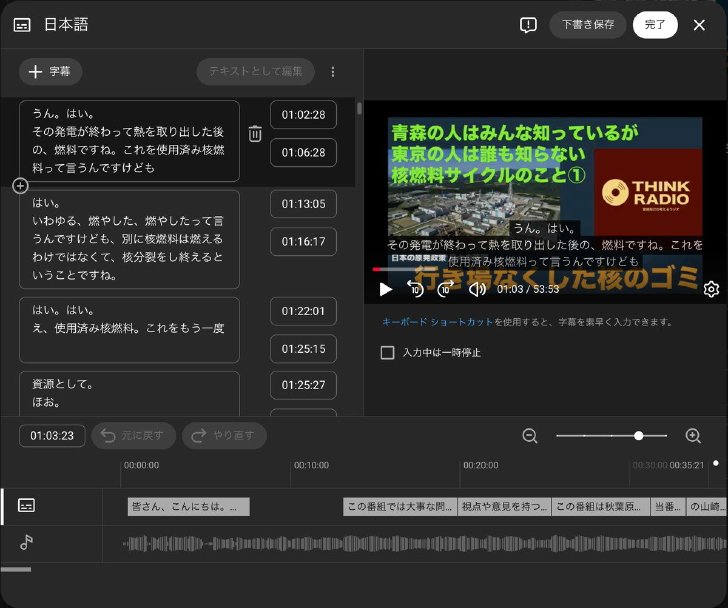 誤変換や表記の揺れは、YouTube Studioの字幕編集機能で動画を再生しながら手作業で実施
誤変換や表記の揺れは、YouTube Studioの字幕編集機能で動画を再生しながら手作業で実施
手作業による修正に多くの時間を食われている現状をそのままにしていたのでは、作業効率が悪すぎる。校正や校閲も可能な限り自動化したい。
校正や校閲も自動化したい
そこで次のステップとして考えているのが、ナレッジベースアプリ「Obsidian」による辞書(ルールベース)を利用した“専門用語に基づく誤変換”の自動修正だ。幸い「考えるラジオ」は、環境問題、原発関連、さらに、閑話休題として音楽や電気自動車の話題と、テーマを絞った形で各番組を収録しているので、各テーマに沿った辞書を構築すれば、校正や校閲もある程度自動化できるはずだ。
例えば、「塩積みの核燃料」を「使用済みの核燃料」、「再生工場」を「再処理工場」といった明らかな誤変換が自動で訂正されるだけでも、かなりの省力化になる。実際、ChatGPTもObsidianでのローカル校閲について、「Whisperの文字起こしとの相性が非常に良いです」と返答してきた。
ただし、ルールベースだと、完全一致の用語については確実な修正は可能だが、用語の辞書を構築しなければならない。もちろん、これもChatGPTが手伝ってくれるのだが、辞書から漏れた言葉の誤変換が残ることになる。
そこで、ルールベースではなく、「LLM(大規模言語モデル)で文脈から判断した上での校正・校閲はできないのか?」とChatGPTに聞いたら、「可能。最終的にはLLMでポストプロセス(後処理)するのが“最強”であり、本命はLLMによるコンテキスト理解+校正」だという。
現状では、文字起こしからのSRTファイル作成に止まっているが、ChatGPTが言うように、LLMを利用したコンテキストを理解しての修正が自動化できたらさらなる省力化が可能になる。
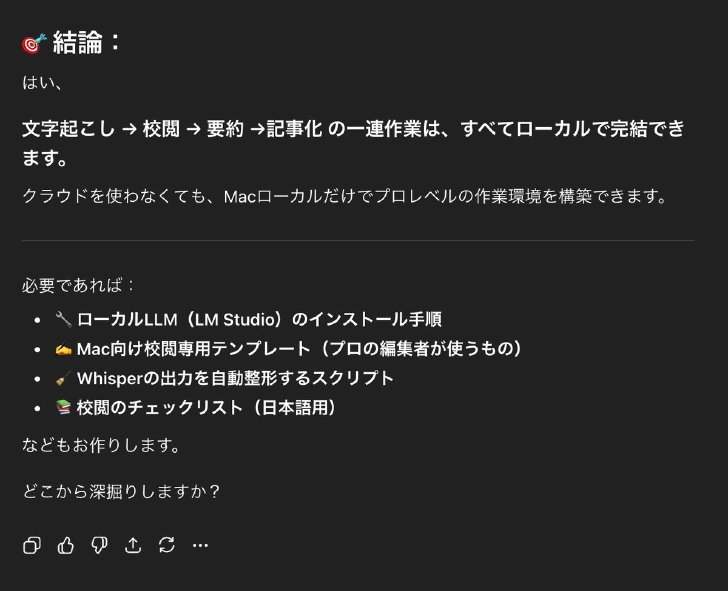 LLMを活用して文脈を理解した上での校正・校閲は可能か?」という問いに対するChatGPTの解答
LLMを活用して文脈を理解した上での校正・校閲は可能か?」という問いに対するChatGPTの解答
今後もそのような仕組みの構築をChatGPTと二人三脚で進め、機会があれば、その過程や校正の精度を今回のような記事として報告できればうれしく思う。
本稿では、動画の字幕作成を実施する環境を実例としてあげた。ただ、この仕組みは動画の字幕だけでなく、インタビューや議事録の文字起こしなど、会話の音声を文字に変換する場面で活用可能だ。ChatGPTに「テキストファイルで書き出して」と頼むだけで良い。この先、この仕組みを進化させ、コンテキストを理解した上での自動校正・校閲が実現すると、記録としての音声録音を多用するビジネスパーソンにとって心強いツールになるのではないだろうか。
著者プロフィール
山崎潤一郎
音楽制作業の傍らライターとしても活動。クラシックジャンルを中心に、多数のアルバム制作に携わる。Pure Sound Dogレコード主宰。ライターとしては、講談社、KADOKAWA、ソフトバンククリエイティブなどから多数の著書を上梓している。また、鍵盤楽器アプリ「Super Manetron」「Pocket Organ C3B3」「Alina String Ensemble」などの開発者。音楽趣味はプログレ。Twitter ID: @yamasakiTesla
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
「痺れるほどにミスを繰り返す」Gemini 3.6 Flashは変わった? 公開から1週間、当初のおバカ回答を今検証する
-
3
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
4
NVIDIA、Microsoft、OpenAIなどがオープンモデル規制反対を表明 Anthropic従業員は「CUDAのオープンソース化が楽しみ」と皮肉
-
5
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
6
Claude、一部チャットがGoogle検索で“丸見え”に 過去には「ChatGPT」でも 漏えいの原因は?
-
7
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
-
8
「Claudeより4割安い」 M365のExcel/メール操作を丸投げる「Copilot Cowork」“従量課金”の落とし穴
-
9
MIXI、新卒エンジニア向け研修資料&動画を無料公開 「実践的なAI活用術」を12科目で紹介
-
10
「Kimi K3」のモデルウェイトと技術レポート公開 日本でも「NVIDIA B300×8」環境での利用報告
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR