KDDI傘下のELYZA、日本語特化の「拡散言語モデル」公開 商用利用も可
KDDIの子会社で、AIを研究開発するELYZA(東京都文京区)は1月16日、日本語に特化した拡散大規模言語モデル(dLLM)「ELYZA-LLM-Diffusion」シリーズを公開した。dLLMは、主に画像生成AIで使われる拡散モデルを言語生成に活用したもの。同シリーズはHugging Faceで公開しており、商用利用もできる。
 ELYZA、日本語特化の「拡散言語モデル」公開(出典:プレスリリース、以下同)
ELYZA、日本語特化の「拡散言語モデル」公開(出典:プレスリリース、以下同)
一般的に言語生成で使われる自己回帰モデルはテキストを冒頭から順に出力する一方、dLLMはテキスト全体を扱いながら出力する。処理の回数を減らして推論を効率化できるため、テキストの生成速度を上げられるほか、将来的にはAIによる電力消費の低減を期待できる。
 自己回帰モデルと拡散言語モデルの出力の違い
自己回帰モデルと拡散言語モデルの出力の違い
そこでELYZAは、電力効率の良い日本語LLM実現に向けた取り組みの一環として、KDDIのGPU基盤を利用し、ELYZA-LLM-Diffusionシリーズを開発した。中国の香港大学が公開しているdLLM「Dream-v0-Instruct-7B」に、約620億トークンの日本語データを学習させて「ELYZA-Diffusion-Base-1.0-Dream-7B」を開発。同モデルに特定のタスクの精度を高める指示学習を実施して「ELYZA-Diffusion-Instruct-1.0-Dream-7B」も開発した。
ELYZAによると、ELYZA-Diffusion-Instruct-1.0-Dream-7Bは、ベースとなったDream-v0-Instruct-7Bや、中国Tencentが公開するdLLM「WeDLM-7B-Instruct(Diffusion)」などに比べ、高い日本語性能を示したという。一方、コーディングや数学を解く一部のタスクでは、他のモデルの性能に及ばなかったとしている。
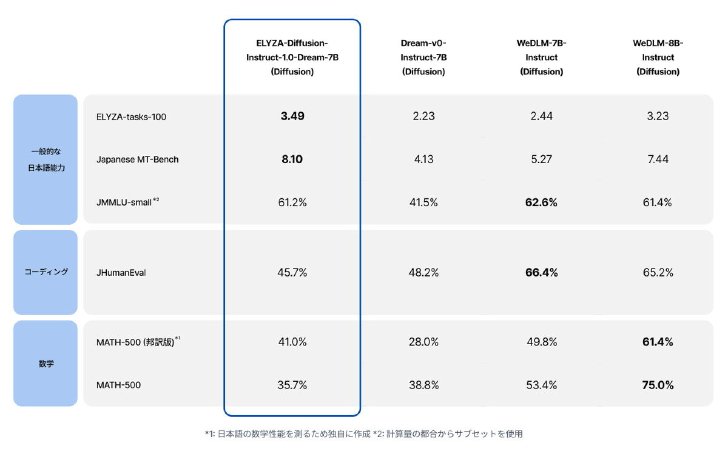 ベンチマークの結果
ベンチマークの結果
ELYZA-Diffusion-Base-1.0-Dream-7Bと、ELYZA-Diffusion-Instruct-1.0-Dream-7Bは共にHugging Faceで公開しており、商用利用もできる。また、チャットAIのUIを模したデモも公開している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
2
Z世代に聞く次の流行、「AIイラスト」が1位に 「Claude Code」も上位
-
3
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
-
4
MIXI、新卒エンジニア向け研修資料&動画を無料公開 「実践的なAI活用術」を12科目で紹介
-
5
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
6
スマホ映像から最短1分で高精細3Dモデル、NECが生成技術を開発
-
7
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
8
「iPhone高騰」はこれからも続く? 中国CXMTに近づくApple、メモリ競合へのけん制が不発に終わりそうなワケ【後編】
-
9
NVIDIA、Microsoft、OpenAIなどがオープンモデル規制反対を表明 Anthropic従業員は「CUDAのオープンソース化が楽しみ」と皮肉
-
10
ゼロから分かる「Claude」の教科書 ChatGPTと比べて分かった強みとは?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR