Innovative Tech
PDF論文やプレゼン資料から「表3を説明して」「5~7ページを要約して」などの指示に回答 米Adobeなど「PDFTriage」開発
Innovative Tech:

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。
Twitter: @shiropen2
米スタンフォード大学と米Adobe Researchに所属する研究者らが発表した論文「PDFTriage: Question Answering over Long, Structured Documents」は、WebページやPDF論文、プレゼンテーション資料などの複雑な構造からなる特定のドキュメントに対するテキストプロントに適切に回答する、大規模言語モデル(LLM)向けの方法を提案した研究報告である。
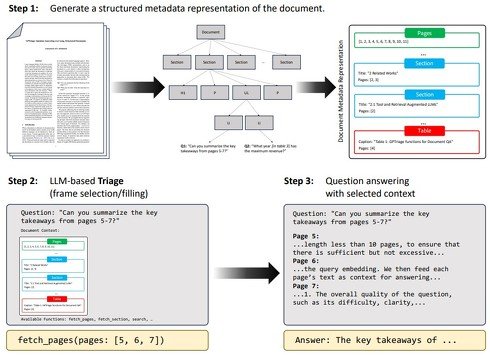 PDFTriage技術の概要
PDFTriage技術の概要
現行の方法では、LLMが対応するコンテキスト数(トークン数)に制限があるため、長い文書から関連するコンテキストを取得する前処理が必要である。だが、多くの文書、例えばWebページやPDF論文、プレゼンテーション資料などは、複雑な構造を持っている。これら構造を持つ文書を単なる平文として扱うのは、ユーザーの期待と合致しない場合が多い。
例として、以下の2つの質問が挙げられる。1つ目は「ページ5-7を要約してください」という明示的な質問で、2つ目は「表3での最大の収益はどの年か?」という暗黙的な質問である。これらの質問に応じるためには、文書の構造情報が不可欠である。
この問題への対策として、「PDFTriage」という新たな手法を提案する。PDFTriageの利用により、特定のページやテーブルを中心とした、文書の構造を踏まえた質問への回答が可能となる。
この方法は、モデルに文書の構造に関するメタデータへのアクセスを持つことで、構造や内容に基づいてコンテキストを取得できる。
具体的には、まずドキュメントの構造化されたメタデータ表現を生成し、セクションのテキストや図のキャプション、ヘッダ、テーブルに関する情報を抽出する。次に、質問が与えられると、質問に答えるために必要なドキュメントのフレームを選択し、選択されたページやセクション、図、またはテーブルから直接それを取得する。最後に、選択された文脈と入力された質問はLLMが処理し、生成した答えを出力する。
このアプローチを評価するために、約900の質問と90の文書からなるデータセットを作成した。このデータセットには、「文書構造の質問」や「表の推論の質問」など、ユーザーが尋ねる可能性のある10の異なるカテゴリーの質問が含まれている。
評価実験の結果、PDFTriageは既存の方法よりも優れたパフォーマンスを示した。さまざまな長さや内容のドキュメントであっても効果的に回答できることが分かった。
Source and Image Credits: Jon Saad-Falcon, Joe Barrow, Alexa Siu, Ani Nenkova, Ryan A. Rossi, Franck Dernoncourt. PDFTriage: Question Answering over Long, Structured Documents.
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech
2019年にスタートした本連載「Innovative Tech」は、世界中の幅広い分野から最先端の研究論文を独自視点で厳選、解説している。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
BASE子会社、最大885万件漏えいか カード番号の一部も ECサイト構築サービスに不正アクセス
-
2
講談社、最大3812件の個人情報流出 社員がフィッシングメールに騙される
-
3
個人情報含む約3300万件のデータ漏えいか 整体院予約など手掛けるEPARKリラク&エステ システムに不正アクセス
-
4
Apple、大量購入品の返品に「15%の手数料」 販売条件に明記 “転売対策”か
-
5
引きこもりはゲーム内でも交流を好まない、奈良先端大が587人調査 「ゲームで社会復帰」に落とし穴?
-
6
「コードは一行も書いていない」 アイドルの宮本佳林さん、AIで配信システムを丸ごと構築 “技術ブログ”が話題
-
7
エルヴィン団長「とりあえず再起動しろ!」──NTT東日本×「進撃の巨人」の“情シスあるある”広告が話題
-
8
Google、パーソナルAI「Gemini Spark」を日本でも利用可能に Chrome統合は米国から
-
9
脳の遺伝子編集治療で6歳女児死亡 1年以上公表されず 約1億3000万円は両親が負担 中国
-
10
ミャクミャク関連サイトがアダルトサイトに……大阪万博のドメイン運用終了→転用続出で物議 悪用の懸念も
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR