
“AI生成の文章/画像だけ”でデータを学習する手法 人間が作るものは一切使わず GoogleとMITが開発:Innovative Tech
Innovative Tech:

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。
Twitter: @shiropen2
米Google Researchや米MIT CSAILに所属する研究者らが開発した論文「Learning Vision from Models Rivals Learning Vision from Data」は、合成画像と合成キャプションから視覚表現を学習するアプローチを提案した研究報告である。「SynCLR」と呼ばれ、実データを使用せずに、最先端の視覚表現学習手法と同等の視覚表現を学習できる。
 (最上段)CLIPのような手法は実際のデータのみから学習、(中段)StableRepのような手法は実際のテキストと生成画像から学習、(最下段)提案手法であるSynCLRは、合成テキストと合成画像から学習する
(最上段)CLIPのような手法は実際のデータのみから学習、(中段)StableRepのような手法は実際のテキストと生成画像から学習、(最下段)提案手法であるSynCLRは、合成テキストと合成画像から学習する表現学習は、生データ(多くの場合ラベルなし)から情報を抽出し整理するプロセスである。現在の最も優れた視覚表現学習手法は、大規模な実データセットに依存している。しかし、実データの収集には問題がある。
大規模な未整理データの収集は比較的安価だが、自己教師あり学習では、データ量が多くなってもスケーリングの効果が少ない。小規模で整理されたデータの収集も可能だが、訓練されたモデルは狭いタスクに限られる。理想的なのは大規模で整理された実画像のデータセットだが、これは高コストである。
この研究では、合成テキストと合成画像のみを使用して視覚表現を学習する新しい手法「SynCLR」を提案する。このアプローチでは、実際のデータセットに依存せずに、完全に合成されたデータを用いる。
具体的には、まず大規模な画像キャプションデータセットを言語モデルを使って合成し、次にテキストから画像を生成するモデルを用いて、それぞれの合成キャプションに対応する複数の画像を生成する。これらの合成画像に対して対照学習を行い、同じキャプションを共有する画像を正のペアとして扱う。

SynCLRは、実世界のデータを直接観察することなく、効果的な視覚的理解を発達させられる。実際のデータセットと競合する性能を持ち、画像分類タスクで他の一般的な視覚表現学習手法(CLIPやDINO v2など)と同等以上の結果を示している。特にセマンティックセグメンテーションなどのタスクにおいては、既存の自己教師あり方法を大きな差で上回っている。
Source and Image Credits: Yonglong Tian, Lijie Fan, Kaifeng Chen, Dina Katabi, Dilip Krishnan, Phillip Isola. Learning Vision from Models Rivals Learning Vision from Data.
関連記事
 画像生成AIに“AIが作った画像”を学習させ続けると? “品質や多様性が悪化” 「モデル自食症」に
画像生成AIに“AIが作った画像”を学習させ続けると? “品質や多様性が悪化” 「モデル自食症」に
米ライス大学と米スタンフォード大学に所属する研究者らは、AI生成画像(合成データ)を用いて別の生成モデルが学習し続けると、その精度にどのような影響がでるのかを検証した研究報告を発表した。 AIが「言語生成AIとの対話」で賢くなり続ける自動成長モデル 米Meta含む研究者らが開発
AIが「言語生成AIとの対話」で賢くなり続ける自動成長モデル 米Meta含む研究者らが開発
米Metaやカナダのマギル大学などに所属する研究者らは、環境と直接対話せずに大規模言語モデル(LLM)からのフィードバックを用いてAIエージェントを強化学習で訓練する手法を提案した研究報告を発表した。 独特な「請求書」「領収書」などの文書を理解する言語モデル「DocLLM」 JPモルガンが開発
独特な「請求書」「領収書」などの文書を理解する言語モデル「DocLLM」 JPモルガンが開発
米JPMorgan AI Researchに所属する研究者らは、複雑なレイアウトを持つ文書(請求書、領収書、契約書、注文書、フォームなど)の自動解析を行う大規模言語モデル(LLM)を提案した研究報告を発表した。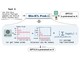 自分の文章がAIに学習されているか調べるツール 米国チームが開発
自分の文章がAIに学習されているか調べるツール 米国チームが開発
米ワシントン大学と米プリンストン大学に所属する研究者らは、任意の文章が大規模言語モデル(LLM)で事前学習されているかを検出できるツールを提案した研究報告を発表した。 壁越しで“部屋の中の声”を盗聴する攻撃 屋内のモノから声の振動をミリ波で検知 米研究者らが開発
壁越しで“部屋の中の声”を盗聴する攻撃 屋内のモノから声の振動をミリ波で検知 米研究者らが開発
米ラトガース大学に所属する研究者らは、人間の話す声によって引き起こされる微細な振動を、部屋の中の物体からミリ波(mmWave)デバイスで検出して声を復元する盗聴攻撃を提案した研究報告を発表した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PRアイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。