Innovative Tech(AI+)
「自称オープンソース生成AI」は本当に“オープン”なのか? 45種のAIモデルをオランダの研究者らが調査
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
オランダのRadboud University Nijmegenに所属する研究者らが発表した論文「Rethinking open source generative AI: open-washing and the EU AI Act」は、オープンソースと主張する生成AIを対象に、どの程度オープンなのかを調査した研究報告である。
 「自称オープンソース生成AI」は本当に“オープン”なのか?
「自称オープンソース生成AI」は本当に“オープン”なのか?
近年、オープンであると主張する生成AIシステムが急増しているが、実際にはどの程度オープンなのかは疑問だ。「オープンソース」と謳いつつ、詳しく見てみると部分的にしか公開していないことはよくある。「オープンソース」は研究やイノベーションに貢献するという考えが含まれており、法的(例えば、5月に成立したEUのAI法案)にも優遇される可能性がある。
そのため、生成AIにおける「オープンソース」の定義は重要な意味を持つようになってきており、その意味を明確にしなければならない。この研究では、14の指標から段階的にオープン性を評価する枠組みを提示し、言語生成モデル40件+ChatGPT、画像生成モデル6件+DALL-Eを調査した。14の指標の詳細は、次に示す通りである。
- データ・モデルの公開状況(ソースコード、訓練データ・モデルの重み、指示調整の訓練データ・指示調整の重み)
- ドキュメンテーション(コード、アーキテクチャ、プレプリント論文、査読済み論文、モデルカード、データシート)
- アクセス・ライセンス(ソフトウェアパッケージ、API、ライセンス形態)
大手企業のモデルほど、訓練データやコードを非公開に
言語生成モデル40件でオープン性が高かったのが「OLMo 7B Instruct」「BloomZ」「AmberCha」「OpenAssistant」などで、ソースコードや訓練データ、モデルの重みなどほとんどが完全公開されていた。
一方で「Llama 3 instruct」「LLaMA2 Chat」「Gemma 7B instruct」「Mixtral 8x7B instruct」などの対象モデルの下位3分の1では、公開は少なく、公開していても限定的で、非公開が多かった。
特に、モデルの重みは公開しているものの、訓練データやコードを公開していないケースが多く「オープンウェイト」と呼んでいる。米Meta、米Google、カナダのCohere、米Microsoft、仏Mistralなどの大手企業のモデルが下位に集中しているのが特徴的である。
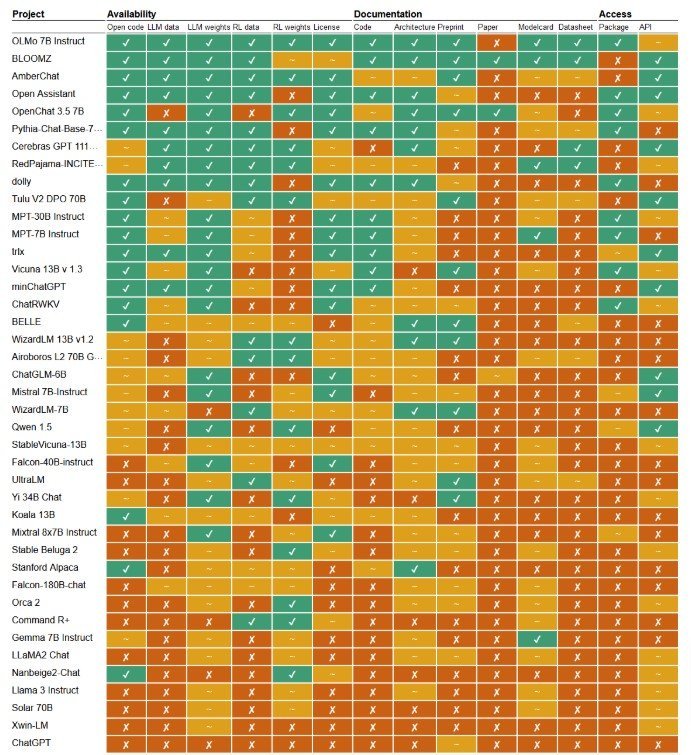 言語生成モデル40件+ChatGPTの結果を示した表 縦がモデル名で横が14の指標 緑色が公開で赤色が非公開、オレンジが部分的に公開
言語生成モデル40件+ChatGPTの結果を示した表 縦がモデル名で横が14の指標 緑色が公開で赤色が非公開、オレンジが部分的に公開
次に、画像生成モデルの評価結果では、6件中5件はほとんどが非公開でオープンとは言い難い結果を示した。しかし、Stable Diffusionだけはほぼ全てを完全に公開しており、対象モデルの中で群を抜いてオープン性が高いことを示した。
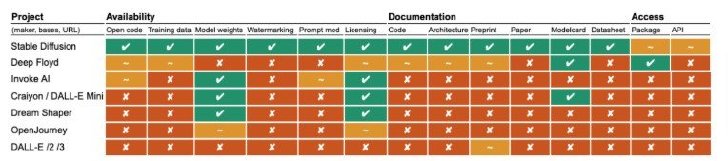 画像生成モデル6件+DALL-Eの結果を示した表
画像生成モデル6件+DALL-Eの結果を示した表
以上の結果から、生成AIにおける「オープンソース」は全てのモデルで公開内容が同じではなく、モデルによって公開内容が異なることが分かった。中でも、「オープンソース」を称しながらも、実際には「オープンウェイト」にすぎないケースも散見された。
特に大手企業によるモデルは、コードやトレーニングデータの詳細を公開しておらず、透明性や説明責任に欠けている。一方、BloomZやStable Diffusionなどの一部のモデルでは、ほぼ完全なオープン性を示していた。
Source and Image Credits: Liesenfeld, A., & Dingemanse, M.(in press). Rethinking open source generative AI: open-washing and the EU AI Act. In The 2024 ACM Conference on Fairness, Accountability, and Transparency(FAccT ’24). ACM.
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Claude、利用制限を全リセット 競合「GPT-5.6」公開と同日……OpenAI幹部「ビビってるね」
-
2
「まるで人間」 OpenAIの新モデル「GPT-Live」のトーク力が話題 間を空けずに考えながら会話できる
-
3
auが生成AI「Stable Diffusion」でリメイクしたお正月CMを放映
-
4
テスラ車内で「Grok」と会話、日本でも展開へ ナビ設定やルート確認を音声で
-
5
デスクトップ版ChatGPT大幅刷新 AIエージェント「Codex」統合、「ChatGPT Work」に
-
6
「生成AIをもう手放せない人」が約6割 逆に“使わなくなったもの”1位は?
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
「Claude Fable 5」サブスク、突如5日間延長 ユーザー悲喜こもごも「寝ずに頑張ったのに」「制限リセットして」
-
9
Claude「サブスク最上位プラン」6カ月間無料で提供 OSS開発者向けキャンペーン、対象を拡大
-
10
「誰にも会わずに帰る店」の寂しさ すかいらーくがロボット配膳の先に挑むAI接客
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR