Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更
米Googleの大規模言語モデル「Gemini 2.0 Flash」が、3月12日(現地時間)に画像生成に対応した。テキストに加え画像の入力が可能で、例えば「この画像のアングルを変えて」「この画像に日本語で文字入れして」という指示にも対応する。XなどのSNSでは、出力物の精度の高さに感心する声が相次いでいる。
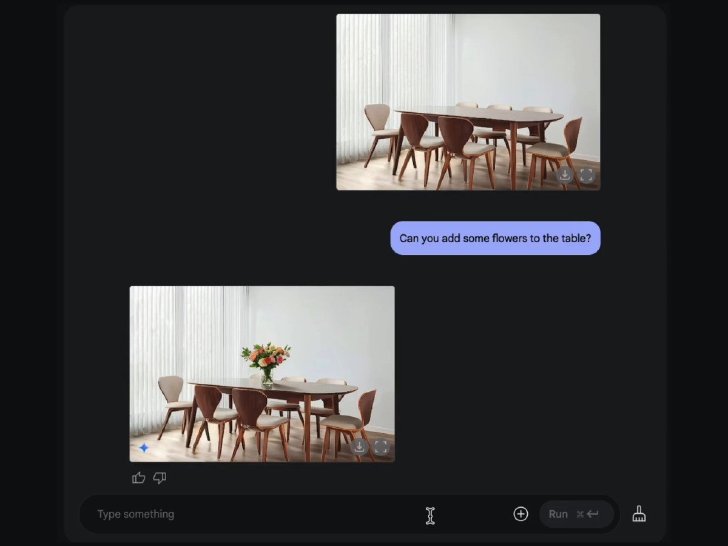 チャットで画像修正(画像はGoogle公式ブログより)
チャットで画像修正(画像はGoogle公式ブログより)
リリース後から、Xではこの画像生成機能を試したユーザーの投稿が続出。画像内の物体の削除/追加やカラーリング、背景の変更などがチャットによる短い指示でできたとの報告が出ている。他にも正面を向いている人物を横から映すといったカメラアングルの移動や、画像内に日本語を正確に入力ができたとする投稿も。その手軽さと性能から「衝撃的」「マンガ制作に使えるのでは」などの意見も見られる。
記者が試したところ、画像内の物体の削除や日本語の追加といった編集が、チャットの指示でできた。カメラアングルの変更も、ゆがみが生じるケースもあったが、大幅な移動に成功。加えて、ラーメンの器を空にした後、器の底に日本語を印刷するといった編集もできた。
 画像内の物体を削除
画像内の物体を削除
 アングルの変更
アングルの変更
 アングル変更の失敗例
アングル変更の失敗例
 日本語の追加
日本語の追加
Gemini 2.0 Flashの画像生成機能は、開発者向けにリリースしたもので、正式版ではない。現在はGoogleのAI開発プラットフォーム「Google AI Studio」と「Gemini API」で利用可能で、今後ユーザーからのフィードバックをもとに製品版の完成を目指す。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
2
MicrosoftやNVIDIAなど、AIのオープンウェイト規制に反対する書簡を公開――Anthropicは署名せず
-
3
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
4
近畿大、入試にAIの利用認める 情報学部の総合型選抜で
-
5
スーパーに並んだ「ごちゃごちゃ生成AIポップ」が物議 “看板王”こと、きぬた歯科院長「これはアリ」
-
6
AI時代、開発チームの人材は“5つの型”に分かれる Claude Code開発責任者の見立て
-
7
Googleが“自社AIの裏切り”に備え始めた 異例の構想「AI Control Roadmap」とは
-
8
NVIDIAフアンCEOが語る“日本復活”のシナリオ 10年続く半導体バブルと「原発活用」の勝算
-
9
アニメ特化動画生成AI「AnimeGen」無償公開、商用利用も可 国内AIベンチャーAIdeaLab
-
10
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR