「異議あり!」――AIが「逆転裁判」をプレイ 最も“推論性能”が高いモデルは? 米大学が実験
ゲーム「逆転裁判」をAIにプレイさせ、推論性能を測る――米カリフォルニア大学サンディエゴ校の研究機関・Hao AI Labは4月16日(日本時間、以下同)、こんな実験の結果を公開した。米OpenAIが15日にリリースしたAIモデル「GPT-4.1」など、最新モデルも含め、複数のAIモデルの性能を比較したという。
逆転裁判は、プレイヤーが弁護士となり、無実の罪を着せられた依頼人を救うゲーム。集めた証拠と、法廷でさまざまな人物が発する証言を比較し、その矛盾を指摘していくことで、真犯人を突き止めるという内容だ。カプコンが2001年に第1作を発売以降、多くの続編が出ており、人気を博している。
Hao AI Labはこのゲームシステムに着目。クリアするためには、矛盾を見つけるための幅広い文脈における推論能力や、証言と食い違う証拠を選ぶ画像分析力、いつ“異議”を唱え、証拠を見せるか作戦を決める能力が必要として、逆転裁判でAIの推論性能を測定した。
実験では、GPT-4.1に加え、OpenAIの「o1」、米Googleの「Gemini 2.5 Pro」「Gemini 2.5 Flash Thinking」、米Anthropicの「Claude 3.7 Sonnet」「Claude 3.5 Sonnet」、米Metaの「Llama 4 Maverick」、中国DeepSeekの「DeepSeek R1」を用意。大規模言語モデル(LLM)にゲームをプレイさせるためのツール「Gaming Agent」を使い、逆転裁判をプレイする能力を比較した。
 AIが「逆転裁判」(英語版)をプレイする様子(1/3、画像は公式Xがポストしか動画と画像より、以下同)
AIが「逆転裁判」(英語版)をプレイする様子(1/3、画像は公式Xがポストしか動画と画像より、以下同)
 AIが「逆転裁判」(英語版)をプレイする様子(2/3)
AIが「逆転裁判」(英語版)をプレイする様子(2/3)
 AIが「逆転裁判」(英語版)をプレイする様子(3/3)
AIが「逆転裁判」(英語版)をプレイする様子(3/3)
結果、逆転裁判のストーリーで起きる4つの事件のうち、o1とGemini 2.5 Proが最高難易度の事件にまで到達。両者ともにクリアには至らなかったが、難しい課題への対応はo1の方がわずかに優れていた。一方APIのコスト効率は、Gemini 2.5 Proが勝り、ケースによってはo1の6~15分の1のコストに抑えられたという。
なお最新モデルのGPT-4.1は、Claude 3.5 Sonnetと同等の性能しか発揮できなかったとしている。
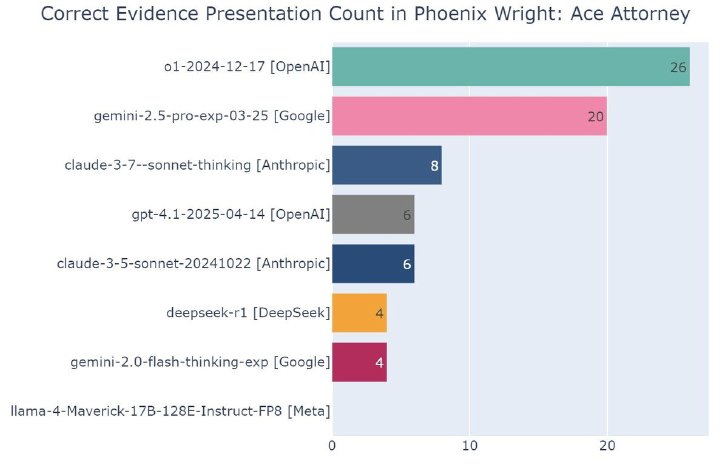 実験における各AIモデルの性能の比較
実験における各AIモデルの性能の比較
AIにゲームのプレイさせる試みとしては、Anthropicが2月からClaude 3.7 Sonnetがゲーム「ポケットモンスター赤」をプレイする様子を配信している。Hao AI Labも、同モデルを含む複数のAIモデルに、ゲーム「スーパーマリオブラザーズ」をプレイさせ、その性能を比較した結果を公表していた。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
キオクシア、株価3分の1急落は「絶好のタイミング」 過去最高益と8000億円自社株買いで示す自信
-
2
「AI、結局使えないじゃん」問題 セールスフォースが431万件対応で導いた正解
-
3
千代田区、Copilot全庁導入で月2000時間削減 10カ月でAIを根付かせた定着の仕掛け
-
4
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
5
月100億トークン使うビズリーチ 「AIコスト増」懸念の中、費用対効果どう判断しているのか
-
6
【レベル14】生成AIを味方に、3D CADを使いこなそう!
-
7
悪用厳禁、「ChatGPT」の会話履歴をごっそりとぶっこ抜く“AIハック”:890th Lap
-
8
WAFを89%すり抜ける事例も──AIが休みなく仕掛けるWeb攻撃、予防策はあるか
-
9
AI・半導体企業トップが語る“稼ぎ頭” キオクシア、フジクラ、東京エレデバの見解まとめ【無料PDF】
-
10
「Qwen3.8-Max」登場、オープン化は「来週」 一部「Fable 5」「GPT-5.6 Sol」超えの性能うたう
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR