Innovative Tech(AI+)
“目を持つAI”は「犬がいる/いない」を区別できない? 否定表現を無視する傾向、OpenAIの研究者らが発表
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
米MITや米OpenAIなどに所属する研究者らが発表した論文「Vision-Language Models Do Not Understand Negation」は、最新の視覚・言語モデル(VLM)が「no」や「not」といった否定表現を理解する能力に深刻な欠陥があることを発見した研究報告だ。
研究チームは、視覚・言語モデルの否定理解能力を体系的に評価するために「NegBench」という新しいベンチマークを開発した。このベンチマークは、画像や動画、医療データセットにまたがる18種類のタスクと7万9千以上のサンプルを含み、2つの主要タスクから構成される。
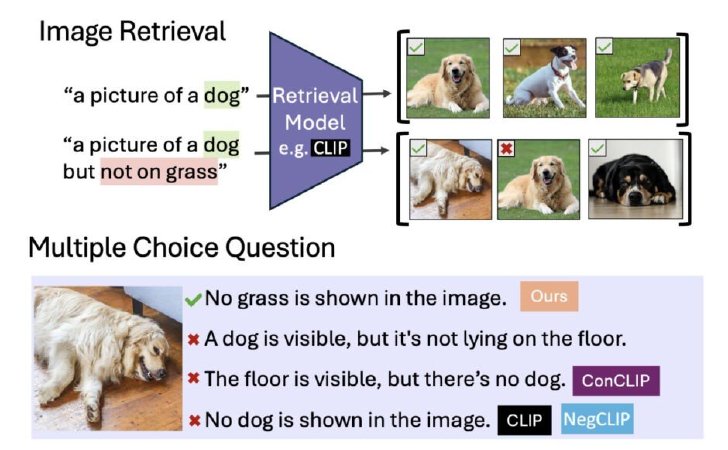 NegBenchでは、画像検索と多肢選択課題を用いて否定理解を評価
NegBenchでは、画像検索と多肢選択課題を用いて否定理解を評価
1つ目は「Retrieval-Neg」と呼ばれる、キャプション否定表現を含む画像探索タスクで、モデルは「窓のない建物」「人のいないビーチの画像」などの条件に合致する画像を検索する。2つ目は「MCQ-Neg」と呼ばれる選択問題で、モデルは画像に対する正しい記述を選ぶ際に否定表現を正確に理解する必要がある。
評価の結果、CLIPをはじめとする現代の視覚・言語モデルは否定理解において深刻な問題を抱えていることが判明した。多くのモデルは否定を含む多肢選択問題でランダム回答程度の精度しか示さなかった。
特に注目すべきは、モデルサイズをViT-B/32(8600万パラメータ)からViT-L/14(3億700万パラメータ)、ViT-H/14(6億3200万パラメータ)にスケールアップしても否定理解が向上しなかった。また最新のSigLIP(ViT-L/14)やAIMV2(LiT)といった発展的なモデルを使用しても、この問題は改善されなかった。
さらに詳細な分析により、これらのモデルが「肯定バイアス」と呼ばれる傾向を持つことが明らかになった。肯定バイアスとは、AIが文章中の「~ない」という否定的な単語のみを無視してしまうことを指す。
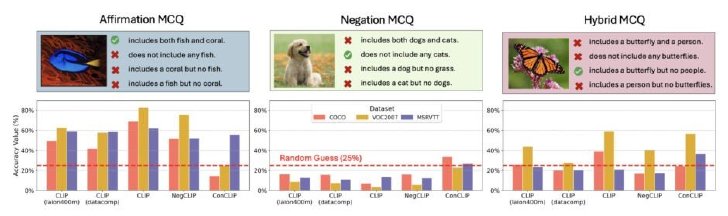 肯定、否定、ハイブリッド(肯定/否定)の文章に対するAIの精度
肯定、否定、ハイブリッド(肯定/否定)の文章に対するAIの精度
例えば、CLIPベースのモデルは「画像に犬がいる」と「画像に犬がいない」を区別できず、否定を表す単語を実質的に無視する傾向がある。また、医療画像の解釈においても同様の問題が観察され、BioMedCLIPやCONCHといった医療特化型モデルでも「肺不透明性がある」と「肺不透明性がない」の区別において大幅な性能低下が見られた。これは胸部X線写真やCTスキャンなどの画像診断の精度に直結する重大な問題である。
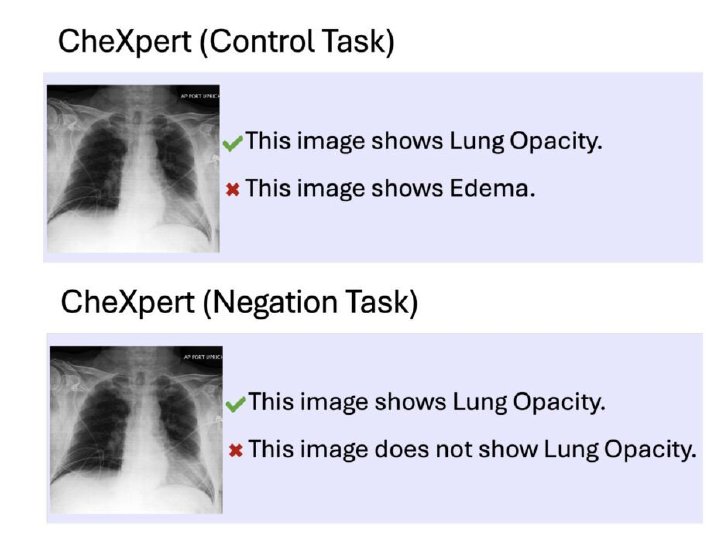 肯定・否定が含まれるタスクサンプル
肯定・否定が含まれるタスクサンプル
この問題に対処するため、研究チームは大規模な合成データセットを作成し、否定理解を向上させるデータ中心のアプローチを提案した。CC12M-NegCapとCC12M-NegMCQという2つのデータセットを生成し、これらを用いてCLIPモデルをファインチューニングした。結果、否定を含むクエリでのリコールが10%向上し、否定キャプションを含む多肢選択問題の精度が約28%向上した。
Source and Image Credits: Alhamoud, Kumail, et al. “Vision-language models do not understand negation.” arXiv preprint arXiv:2501.09425(2025).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
AIに頼ると技術が落ちる? 医師・エンジニアたちの懸念、検証結果は……Natureも警鐘
-
2
Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用
-
3
画面操作を“録画”→AIが作業代行 Codexに新機能「Record & Replay」
-
4
千葉県印西市はなぜ「データセンターの聖地」になったのか Google、Microsoftを呼び込んだ半世紀前の“読み違い”
-
5
「ChatGPTにうちの会社が出てこない」──採用担当を悩ます“AI就活時代”の容赦なき実態
-
6
Anthropicへの500万ドル間接出資を解消、広告事業のイオレ 軸足移すAIデータセンター事業に資金投入
-
7
工数「76%」削減 味の素グループが「経理AIエージェント」導入で先陣を切れたワケ
-
8
OpenAIが明かす、新職種「FDE」の実態 半年で様変わり、「仕事の7割が消滅」したことも
-
9
「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験
-
10
赤字7500億円で時価総額300兆円 SpaceX上場が突きつけた「AIの適正価格」
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR