日本語に強いVLM「Sarashina2-Vision」 ソフトバンクのAI開発企業が公開 MITライセンスで商用利用OK
ソフトバンクの子会社でAIの研究開発などを手掛けるSB Intuitions(東京都港区)は3月17日、日本語に強い大規模視覚言語モデル(VLM)「Sarashina2-Vision(8B・14B)」を公開した。同社独自の大規模言語モデル(LLM)「Sarashina2」シリーズをベースに開発したAIモデル。MITライセンスで、商用利用も可能だ。
Sarashina2-Visionは、特に日本語や日本の文化・慣習に強いAIモデルとして構築。日本に関連する画像のタスク処理能力を評価したところ、複数の日本語ベンチマークで国内最高の性能を実現したという。80億パラメータの8Bと、140億パラメータの14Bのどちらも同社のHuggingFace Hubページで公開中。
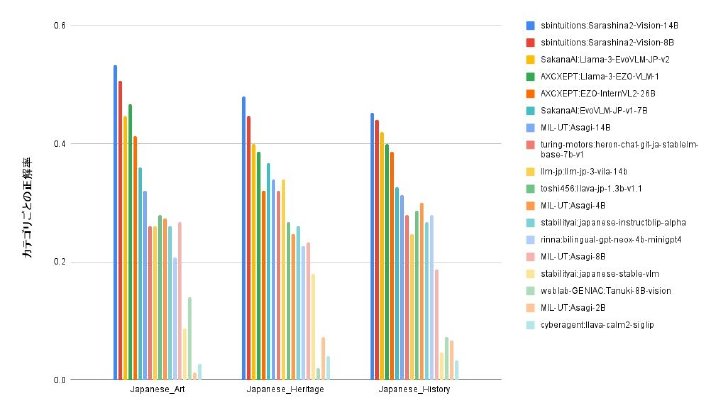 他VLMとの性能比較
他VLMとの性能比較
VLMとは、画像とテキストを複合して扱えるマルチモーダルなAIモデル。画像とテキストを理解できることで「この写真に写っているものは何ですか?」のような質問に対応できる。
Sarashina2-Visionに東京タワーが写った写真を提示し「この写真に写っているもので、最も有名と考えられる建築物は何でどこに写っていますか?」と質問すると、「この写真に写っているもので、最も有名と考えられる建築物は東京タワーです。東京タワーは、東京のランドマークであり、この写真では、ビル群の向こうに写っています」と回答するという。
 Sarashina2-Visionの回答例
Sarashina2-Visionの回答例
VLMのチューニングにおいて、高品質な画像指示チューニングデータセットは欠かせない。しかし、日本語のこれらのデータセットを確保するのが難しいのが現状という。公開済みのデータセットが少なく、人手によるデータ作成はコストが高く大量のデータの用意が困難であること、公開されている場合もライセンスの制限などの問題があるためだ。
これらの課題を解決するため、SB Intuitionsでは合成データセットを活用し、不足分を補った。これにより「一定の品質のデータを大量に作成できる」「目的に応じたタスク特化のデータを作成できる」などのメリットも得られ、VLMの性能向上を実現できたとしている。
 合成データセットの例
合成データセットの例
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
アクセスランキング
-
1
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
2
Z世代に聞く次の流行、「AIイラスト」が1位に 「Claude Code」も上位
-
3
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
「iPhone高騰」はこれからも続く? 中国CXMTに近づくApple、メモリ競合へのけん制が不発に終わりそうなワケ【後編】
-
6
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
7
スマホ映像から最短1分で高精細3Dモデル、NECが生成技術を開発
-
8
MIXI、新卒エンジニア向け研修資料&動画を無料公開 「実践的なAI活用術」を12科目で紹介
-
9
なぜ、Microsoft 365 Copilotは「会社の仕事を理解する」のがうまいのか?
-
10
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR