Innovative Tech(AI+)
全てのAI言語モデルは、プラトンが説く「イデアの世界」を共有して見ている? 米コーネル大学が研究
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
古代ギリシャの哲学者プラトンは、私たちが見ている世界は真の実在(イデア)の影にすぎないと説いた。このイデア論では、例えば、個々の美しいものの背後には完全な「美のイデア」が存在し、全ての犬の背後には永遠不変の「犬のイデア」が存在し、目に見える「美しい花」も「犬」もそのイデアの影にずぎないという考えだ。この2300年以上前の洞察が、現代の人工知能研究に新たな光を投げかけている。
米コーネル大学の研究チームが発表した論文「Harnessing the Universal Geometry of Embeddings」は、まさにこのイデア論を人工知能の世界に適用したものだ。
異なる企業や研究機関が開発したAIモデルは、それぞれ独自の方法で言葉を数値化しているが、実は全て同じ「意味のイデア界」を捉えようとしているのではないか。この仮説を実証し、さらにその普遍的構造を利用可能にしたのが「vec2vec」という今回提案する技術だ。
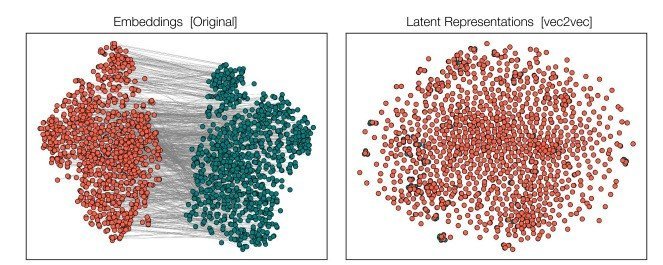 異なるAIモデル(赤:GTR、緑:GTE)の埋め込みベクトルが元は離れているが(左)、vec2vec変換後の潜在空間では重なり合う(右)様子
異なるAIモデル(赤:GTR、緑:GTE)の埋め込みベクトルが元は離れているが(左)、vec2vec変換後の潜在空間では重なり合う(右)様子
「猫」「cat」「chat」「Katze」これらは全て異なる音の連なりだが、同じ概念を指している。同様に、自然言語処理モデルである米Googleの「BERT」も、米OpenAIの「CLIP」も、米Metaの「RoBERTa」も、それぞれ異なる数値ベクトルで単語や文章を表現するが、その根底では同じ意味構造を共有しているはずだ。vec2vecは、この共通の意味空間を発見し、活用する。
技術的には、vec2vecは敵対的学習とサイクル一貫性という手法に触発されている。これは「影から実在を推測する」過程を数学的に実現したようなもので、あるモデルの埋め込みベクトル(影)から、普遍的な潜在表現(イデア)を経由して、別のモデルの埋め込みベクトル(別の角度からの影)へと変換する。この変換は元の文章を一切見ることなく、ベクトルの幾何学的パターンだけから学習される。
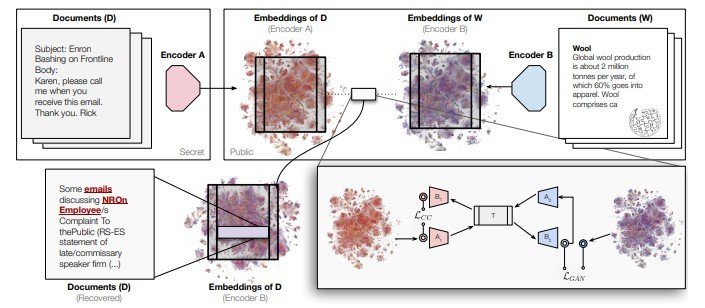 vec2vecが未知のAIモデルの埋め込みベクトルを既知モデルの空間に変換し、元の文書情報を抽出する仕組み
vec2vecが未知のAIモデルの埋め込みベクトルを既知モデルの空間に変換し、元の文書情報を抽出する仕組み
実験結果は、AIモデルがデータをどのように表現・処理するかの研究「プラトニック表現仮説」の正しさを示している。
全く異なるアーキテクチャを持つモデル間でも、vec2vecによる変換後のベクトルは最大92%の類似度を達成。さらに、ウィキペディアで訓練したモデルが、SNSの投稿や医療記録といった全く異なる種類のテキストでも同様の性能を発揮したことが分かった。これは発見された意味構造が特定のドメインに依存しない、真に普遍的なものであることを示唆している。
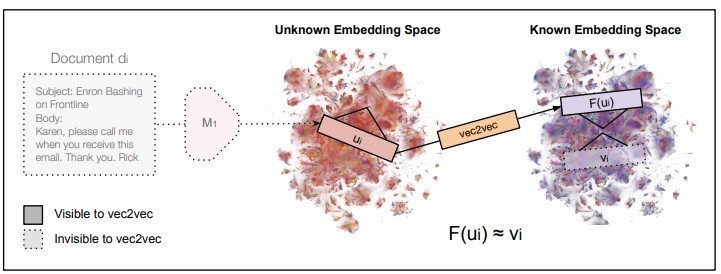 vec2vecが元文書やエンコーダーにアクセスせずに、未知モデルの埋め込みベクトル(中央)のみから既知モデル空間への変換(右)を実現する図
vec2vecが元文書やエンコーダーにアクセスせずに、未知モデルの埋め込みベクトル(中央)のみから既知モデル空間への変換(右)を実現する図
一方、この技術が倫理的問題も提起している。vec2vecが可能にするイデアへのアクセスは、悪用される危険性を孕んでいる。研究チームは、変換されたベクトルから元の文書の内容を推測できることを実証した。
具体的には、個人名、日付、金銭情報、医療記録などを抽出できた。特定のモデルペアでは、最大80%の何らかの情報漏えいが確認されており、プライバシー侵害のリスクが懸念される。
 vec2vec変換後のベクトルから元の文書内容(企業名、人名、経費報告など)が部分的に推測可能であることを示す実例
vec2vec変換後のベクトルから元の文書内容(企業名、人名、経費報告など)が部分的に推測可能であることを示す実例
Source and Image Credits: Jha, Rishi, et al. “Harnessing the universal geometry of embeddings.” arXiv preprint arXiv:2505.12540(2025).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
2
【2025年12月】ChatGPT、Gemini、Claudeの企業向けプランを徹底比較 “コスパ”以外の選定ポイントにも注目
-
3
ゲームエンジン「Godot」AI生成コードを原則禁止へ レビュアー疲弊「機械と話したくない」
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
Meta、「Claude Codeと組織改編で爆速開発」のはずが「想定より加速せず」 ザッカーバーグ氏、社内集会で発言
-
6
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
7
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
8
任天堂、生成AIに対する考えを明かす 古川社長「ゲーム開発とAI技術はもともと近い」一方……
-
9
国内大手ロボットメーカー3社が協力、「フィジカルAI」向けデータセット構築へ
-
10
「Claude Fable 5」の性能が落ちた? 提供停止前後で比べた結果 米AI企業2社がそれぞれ報告
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR