Innovative Tech(AI+)
「著作権トラップ」――生成AIに作品を“無断盗用”されたか後から証明する方法 英ICLなどが開発
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
英インペリアル・カレッジ・ロンドンなどに所属する研究者らが発表した論文「Copyright Traps for Large Language Models」は、大規模言語モデル(LLM)の訓練データに著作権所有者の作品が含まれているかを特定する方法を開発した研究報告である。これは、著者や出版社が自分の作品にさりげなく印を付け、それがAIモデルで使われたかどうかを後で検出できるようにする用途を目的としている。
 生成AIに作品を無断盗用されたか後から証明する方法 英ICLなどが開発
生成AIに作品を無断盗用されたか後から証明する方法 英ICLなどが開発
LLMの学習プロセスで使用されるデータの中に、著作権で保護された内容が含まれていることが問題視されている。この状況を受け、研究者たちは特定の文章がLLMの学習に使われたかどうかを判定する方法を開発した。
この技術は、20世紀の地図作成者たちが不正コピーを検出するために架空の町を地図に入れていたことからヒントを得ている。研究チームは「著作権トラップ」(Copyright Traps)と呼ばれる独自の架空の文章を原文に挿入することで、訓練済みLLMにおけるコンテンツの検出可能性を研究した。
この方法では、著作権所有者が複数の文書にわたって著作権トラップを繰り返し挿入する。その後、LLM開発者がそのデータをスクレイピングして訓練に使用した場合、モデルの出力に現れる不規則性を観察することで、そのデータが訓練に使用されたことを証明できるようになる。
研究チームは、この手法の有効性を検証するため「CroissantLLM」という13億パラメータAIモデルを使用して実験をした。このモデルは3兆個のトークン(おおよそ単語数の意)で学習されている。訓練用データセットにさまざまな著作権トラップを挿入し、LLMに学習させ、モデルの出力を観察した。これらのトラップ文は、長さ(25、50、100トークン)や挿入回数(1、10、100、1000回)を変えて生成した。
実験の結果、短い文(50トークン以下)を100回程度繰り返しても、効果的に検出できないことが分かった。しかし、100トークンの文を1000回繰り返すと、高い精度で検出可能であることが判明した。この結果は、長い文を多数回繰り返すことで、著作権トラップが効果を発揮することを示している。また、予測が困難な文章ほど検出されやすいことも分かった。
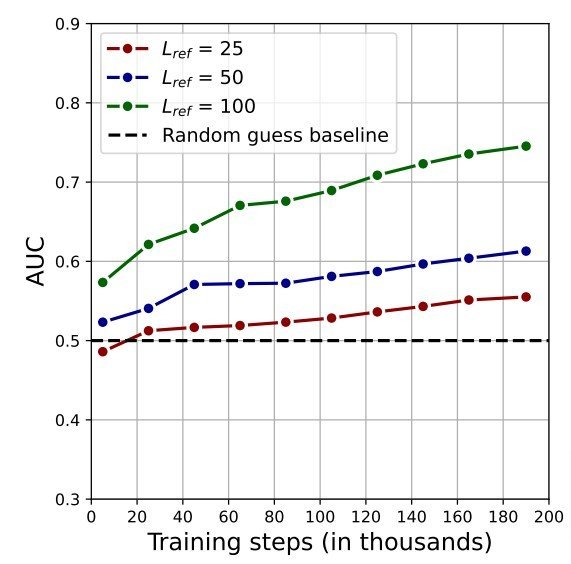 異なる長さ(25、50、100トークン)の合成トラップ文を1000回繰り返し挿入した場合のトレーニング過程における著作権トラップの検出性能の変化
異なる長さ(25、50、100トークン)の合成トラップ文を1000回繰り返し挿入した場合のトレーニング過程における著作権トラップの検出性能の変化
このような訓練時にデータを記憶する能力を利用した攻撃を「メンバーシップ推論攻撃」といい、研究が進んでいる。この手法は、訓練中に大量のデータを記憶する大規模な最先端モデルで効果的に機能する。一方で、小規模なモデルは、記憶する量が少ないため、この攻撃を受けにくいとされていた。しかし、今回の「著作権トラップ」は小規模なモデルでも通用することを実証した。
Source and Image Credits: Meeus, Matthieu, et al. “Copyright Traps for Large Language Models.” arXiv preprint arXiv:2402.09363(2024).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
2
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
3
ローカルLLMは本当に手元で動くのか? ハードウェアとモデルの現実的な選び方【2026年春】
-
4
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
5
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
6
ループエンジニアリングとは? チャットとAIコーディングの往復から卒業する新しい開発スタイル
-
7
東電出資に意欲 孫正義氏が「国内データセンター誘致」で狙うインフラ戦略
-
8
【解説】キオクシアなぜ急成長? 半導体メモリって何? AIブームを見通すための基礎知識
-
9
OpenAI、次世代「GPT-5.6」シリーズを限定プレビュー 米政府と調整、命名は「Sol/Terra/Luna」に刷新
-
10
AIコーディングはなぜ後から苦しくなるのか? 技術負債に続く「理解負債」「認知負債」という新たな落とし穴
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR