“AIを評価するAI”でハルシネーションを大幅低下 AI insideが独自技術 “SLM”との組み合わせで挑むビジネス戦略とは
AIスタートアップのAI inside(東京都渋谷区)は10月28日、AIを評価するAI「Critic Intelligence」(以下CI)を開発したと発表した。同社は日本語ドキュメント処理に特化した大規模言語モデル(LLM)「PolySphere-2」を提供しているが、CIを使うことで、ハルシネーションの出現率を大幅に低下させることに成功。GPT-4oやClaude 3.5 SonnetなどのAIモデルと比べても抑えられているという
 AIを評価するAI「Critic Intelligence」 AI insideが開発
AIを評価するAI「Critic Intelligence」 AI insideが開発
PolySphere-2の特徴は、ハルシネーションの出現率の低さだ。日本語ドキュメントの処理タスクにおいて同社が評価したところ、出現率0.25%を記録。これはGPT-4oの33.69%や、Claude 3.5 Sonnetの19.17%よりも大幅に抑えられていると、同社は説明している
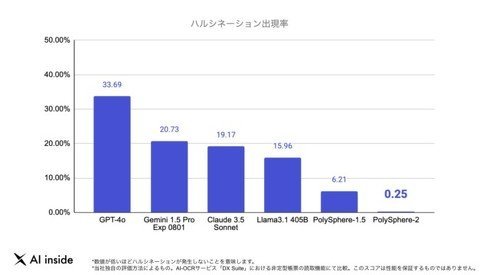 AI insideが公表したハルシネーションの出現率の比較
AI insideが公表したハルシネーションの出現率の比較
ハルシネーションの出現率を大幅に抑えた仕組みが、同社が開発したCIになる。これは「(ドキュメント処理時などの)文字の掠れによる誤読や、ハルシネーションなどによる誤りの確率を明らかにすることで、AIが生成した出力結果の正確性を評価するAI」という。
同社の渡久地択CEOはCIの仕組みついて「他のAIのアウトプットデータとインプットデータを比べて整合性があるかを測る。これはRAGなどの特定のデータベースを参照し確認するということではなく、人間が気にしない、もしくは分からないような情報を参照し、AIの間違いを探す仕組みだ」と話す。
 渡久地択CEO
渡久地択CEO
AIが正誤判断に使う情報の例として挙げたのは「ファクスで届いた書類は、スキャンされたデータよりも読みにくい」「横長の紙に書かれた文字列は長く、間違えが生じやすい」など。人間には何の変哲もないような情報だが、AI独自の審査基準で正誤判断を行うという。またOCR以外にも、音声やテキスト、画像などにも応用が効く技術であるとし、同社はCIの特許を出願中であるとしている。
「LLMでビジネスを戦っていく必要はない」
企業における生成AI導入の大きな課題であるハルシネーションに、独自技術で対策をとるAI inside。そんな同社は8月から、PolySphere-2に企業が持つデータを学習・ファインチューニングすることで、その企業オリジナルのSLMを構築できるサービスを提供している。
 企業オリジナルSLMの構築サービスを8月から提供中
企業オリジナルSLMの構築サービスを8月から提供中
SLMとは「Small Language Mode」の略称で、日本語では小規模言語モデルといわれる。小さいパラメータ数を持つAIモデルで、消費する計算リソースが少ないため、スマートフォンなどの端末上でも動かせる。また、特定のタスクに特化したファインチューニングを実施しやすいのも特徴だ。
企業向けAIモデルのカスタマイズサービスにおいて、LLMではなくSLMを提供するにも理由があると渡久地CEOは話す。
「われわれはLLMを蒸留(AIモデルを圧縮して効率を上げる技術)することで、SLMを作っていく。なぜならそもそもLLMでビジネスを戦っていく必要がないと考えている。例えば、売り上げを説明できるAIを開発したいとき、別にそのAIはハンバーグのレシピを答えれられる必要はない。当社は、SLMでマルチにAIエージェントを展開してくのが正しいと考えている」(渡久地CEO)
この考えのもと、日本語ドキュメント処理に特化したLLM・PolySphere-2を開発。この精度を極限まで高めるため、CIの開発にも至ったという。また、同社のAI-OCRサービス「DX Suite」には2025年初頭ごろにAIエージェントも標準搭載する予定だ。AIエージェントとは、自律的に考えて必要なタスクを実行するプログラムのことで、DX SuiteではまずAI-OCR処理後の人によるデータチェック工程をAIで自動化する。
渡久地CEOは「われわれは、AIがツールではなく共に働くバディとして利用される働き方『Work with Buddy』を実現していきたい」と今後の意気込みを語った。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験
-
2
AIで要らなくなったSaaS、要るSaaSは、どれ? 日本の「SaaS is dead」の実態
-
3
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
4
ChatGPT vs. Google検索──どっちで調べるのが学習効果が高い? 8日間の実験で検証した研究
-
5
赤字7500億円で時価総額300兆円 SpaceX上場が突きつけた「AIの適正価格」
-
6
画面操作を“録画”→AIが作業代行 Codexに新機能「Record & Replay」
-
7
高級セレクトショップ「バーニーズ」が新品と中古の二刀流 富裕層の「初めての中古購入」を狙うワケ
-
8
米大企業の7割が導入する「Databricks」とは何者か? 評価額20兆円の「AI向けデータ基盤」
-
9
工数「76%」削減 味の素グループが「経理AIエージェント」導入で先陣を切れたワケ
-
10
月間売上1億円超、“推しAI”アプリ「Zeta」がオタク女子わしづかみ ただし危うさも
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR