初の“長考”できる国産フルスクラッチLLM「PLaMo 3.0 Prime」 Qwen3-235Bやgpt-oss-120bに肉薄 PFN
Preferred Networksは3月19日、既存モデルを下敷きにせず、ゼロベースで構築した大規模言語モデル「PLaMo 3.0 Prime」のβ版をリリースした。中国産モデル「DeepSeek R-1」などの開発手法を参考に、同様の形で開発したモデルとしては国内で初めて、長考によってクオリティーの高い回答(reasoning)が可能な機能を搭載した。現在、無償利用を前提にモニター企業を募っている。
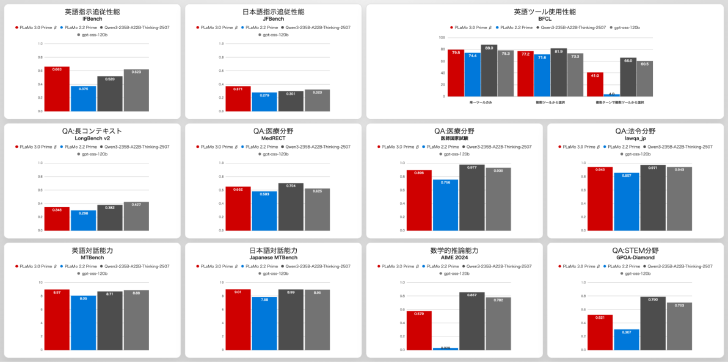 ベンチマーク(ニュースリリースから引用)
ベンチマーク(ニュースリリースから引用)
ベンチマークでは日本語・英語による指示への追従性能や対話能力で「Qwen3-235B-A22B-Thinking-2507」や「gpt-oss-120b」(長考の程度は3段階で中)に勝り、医療・法令分野も肉薄。ただし数学や、英語ツールの利用性能のうち、複数の段階で多数のツールから選んで使う能力は大きく劣った。
コンテキスト長は入力64Kトークン・出力20Kトークンと、旧モデル「PLaMo 2.2 Prime」の入力32Kトークン・出力4Kトークンから拡大した。ただしこちらも「DeepSeek V3.2」や「GPT-5.2」といったモデルには劣るため、苦手なタスクへの対応能力と合わせて今後の改善を目指す。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
AIに頼ると技術が落ちる? 医師・エンジニアたちの懸念、検証結果は……Natureも警鐘
-
2
Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用
-
3
「ChatGPTにうちの会社が出てこない」──採用担当を悩ます“AI就活時代”の容赦なき実態
-
4
画面操作を“録画”→AIが作業代行 Codexに新機能「Record & Replay」
-
5
千葉県印西市はなぜ「データセンターの聖地」になったのか Google、Microsoftを呼び込んだ半世紀前の“読み違い”
-
6
Anthropicへの500万ドル間接出資を解消、広告事業のイオレ 軸足移すAIデータセンター事業に資金投入
-
7
工数「76%」削減 味の素グループが「経理AIエージェント」導入で先陣を切れたワケ
-
8
「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験
-
9
OpenAIが明かす、新職種「FDE」の実態 半年で様変わり、「仕事の7割が消滅」したことも
-
10
赤字7500億円で時価総額300兆円 SpaceX上場が突きつけた「AIの適正価格」
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR