Innovative Tech
大規模言語モデルの「幻覚」を軽減する32の最新テクニック バングラデシュなどの研究者らが発表
Innovative Tech:

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。
Twitter: @shiropen2
バングラデシュのIslamic University of Technology、米サウスカロライナ大学、米スタンフォード大学、米Amazon AIに所属する研究者らが発表した論文「A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models」は、大規模言語モデル(LLM)における幻覚(AIが根拠のないコンテンツを生成すること、ハルシネーションともいう)を軽減するための32のテクニック(研究)を紹介した研究報告である。
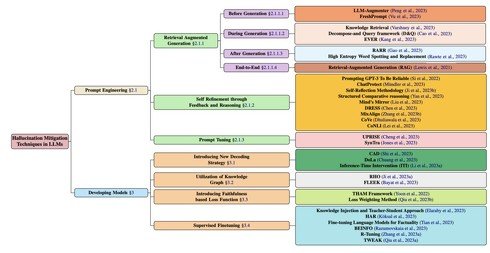 LLMにおける幻覚軽減技術を分類した表
LLMにおける幻覚軽減技術を分類した表
これらのテクニックには、生成前や生成中、生成後のさまざまな段階で外部情報を取り入れることでより正確な回答を引き出すもの、言語モデル自体を改良して誤った情報の生成を減らすものなど、異なるアプローチに分類されている。以下に、それぞれのテクニックを簡潔に説明する。
- LLM-Augmenter(Peng et al., 2023):外部知識に基づいてLLMの応答を生成するシステム。
- FreshPrompt(Vu et al., 202):検索エンジンから取得した関連する最新情報をプロンプトに組み込むことで、パフォーマンスを向上させる手法。
- Knowledge Retrieval(Varshney et al., 2023):テキスト生成中に可能な幻覚を検出し軽減する手法。
- Decompose-and-Query framework (D&Q)(Cao et al., 2023):複雑な問いに対して、外部知識を基にした分解と問い合わせを行い、信頼性の高い回答を生成。
- EVER(Kang et al., 2023):生成中に幻覚を検出し修正するリアルタイムの戦略。
- RARR(Gao et al., 2023):生成したテキストの根拠を後処理で検証し、信頼性を高める方法。
- High Entropy Word Spotting and Replacement(Rawte et al., 2023):高エントロピー単語(予測が難しいまたは不確実性が高い単語)を検出し置換することで幻覚を軽減。
- Retrieval-Augmented Generation(RAG)(Lewis et al., 2021):事前学習済みの言語モデルとWikipediaのデータベースを組み合わせることで、生成したテキストの品質を向上させる。
- Prompting GPT-3 To Be Reliable(Si et al., 2022):GPT-3の信頼性を高めるための効果的なプロンプトを提案。
- ChatProtect(Mundler et al., 2023):自己矛盾を検出し軽減するプロンプトベースのフレームワーク。
- Self-Reflection Methodology(Ji et al., 2023b):医療QAシステムの幻覚を軽減するための反復的な自己反省方法。
- Structured Comparative Reasoning(Yan et al., 2023):テキスト間の類似点と相違点を明確に比較し、一貫性を向上させ、自然言語処理タスクにおける精度を高める手法。
- Mind’s Mirror(Liu et al., 2023):大規模言語モデルが持つ自分自身の推論を評価する能力を、小型言語モデルに蒸留し、幻覚を軽減。
- DRESS(Chen et al., 2023):自然言語フィードバックを使用してモデルのアライメント(人間の好みや期待に合わせる能力)を改善。
- MixAlign(Zhang et al., 2023b):言語モデルを使って、ユーザーの質問と外部知識の間の矛盾やズレを自動的に検出・修正。
- CoVe(Dhuliawala et al., 2023):モデルが初期の回答を生成した後、その回答をファクトチェックするための確認質問を計画し、それらの質問に回答し、最終的な検証済みの回答を生成。
- CoNLI(Lei et al., 2023):背景コンテキストが提供された場合にLLMによって生成する幻覚の検出と軽減。
- UPRISE(Cheng et al., 2023):特定の問題(ゼロショットタスク)に適した手掛かり(プロンプト)を自動で選び出すシステム。
- SynTra(Jones et al., 2023):合成タスク(モデルが間違った情報を生成しやすい特別なタスク)で学習させ、要約タスクでの幻覚を効率的に軽減。
- CAD(Shi et al., 2023):コンテキストと矛盾するモデルの事前知識を上書きし、より信頼できる現在の情報に基づいて優先知識を置き換える手法。
- DoLa(Chuang et al., 2023):LLMの異なる層(前段と後段)から得られるデータ(ロジット)の違いを利用して、次に出てくるべき単語や文の確率をより正確に計算する手法。
- Inference-Time Intervention(ITI)(Li et al., 2023a):推論中にモデルの考え方を少し変えて、LLaMAモデルの真実性を向上させる。
- RHO(Ji et al., 2023a):言語モデルとナレッジグラフを組み合わせることで、より忠実な応答を生成する手法。
- FLEEK(Bayat et al., 2023):入力テキスト内の検証可能な事実を自動的に識別し、それらを検証して修正するためのツール。
- THAM Framework(Yoon et al., 2022):ビデオに基づく対話システムで発生するテキスト幻覚を軽減する手法。
- Loss Weighting Method(Qiu et al., 2023b):多言語における要約生成時の幻覚を軽減するために、トレーニングサンプルの損失を信頼度スコアに基づいて重み付けする手法。
- Knowledge Injection and Teacher-Student Approach(Elaraby et al., 2023):パラメータ数が少ないオープンソースLLM(例えばBLOOM 7B)での幻覚を測定し軽減するためのフレームワーク。
- HAR(Koksal et al., 2023):幻覚を利用して作成した反事実的データセット(事実とは異なるデータ)を使用して、モデルが関連する情報や文脈をテキストから適切に抽出し、理解する能力を改善。
- Fine-tuning Language Models for Factuality(Tian et al., 2023):人間の介入なしで自動で情報が正しいかチェックする方法と、プログラムが良い答えを好むように学習する方法を使って、LLMをより事実に基づいたものにする手法。
- BEINFO (Razumovskaia et al., 2023):情報を探す対話での回答の正確さを高めるために、特別な調整方法を適応。
- R-Tuning (Zhang et al., 2023a):モデルが自身の知識範囲外の質問に対して回答を拒否する能力を向上させる手法。
- TWEAK (Qiu et al., 2023a):生成したテキストを仮説として扱い、それが与えられた情報をどれだけ正確にサポートしているかを評価し、品質への影響を最小限に抑えながら、信頼性を向上させる方法。
Source and Image Credits: Tonmoy, S. M., et al. “A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models.” arXiv preprint arXiv:2401.01313(2024).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech
2019年にスタートした本連載「Innovative Tech」は、世界中の幅広い分野から最先端の研究論文を独自視点で厳選、解説している。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
BASE子会社、最大885万件漏えいか カード番号の一部も ECサイト構築サービスに不正アクセス
-
2
講談社、最大3812件の個人情報流出 社員がフィッシングメールに騙される
-
3
個人情報含む約3300万件のデータ漏えいか 整体院予約など手掛けるEPARKリラク&エステ システムに不正アクセス
-
4
Apple、大量購入品の返品に「15%の手数料」 販売条件に明記 “転売対策”か
-
5
引きこもりはゲーム内でも交流を好まない、奈良先端大が587人調査 「ゲームで社会復帰」に落とし穴?
-
6
「コードは一行も書いていない」 アイドルの宮本佳林さん、AIで配信システムを丸ごと構築 “技術ブログ”が話題
-
7
エルヴィン団長「とりあえず再起動しろ!」──NTT東日本×「進撃の巨人」の“情シスあるある”広告が話題
-
8
Google、パーソナルAI「Gemini Spark」を日本でも利用可能に Chrome統合は米国から
-
9
脳の遺伝子編集治療で6歳女児死亡 1年以上公表されず 約1億3000万円は両親が負担 中国
-
10
ミャクミャク関連サイトがアダルトサイトに……大阪万博のドメイン運用終了→転用続出で物議 悪用の懸念も
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR