GeForce6800 シリーズに秘められたNVIDIA の戦略とは?(中編)(1/2 ページ)
 今回もお相手は前回に引き続き、NVIDIA Vice President&Technical Marketingを務めるTトニー・タマシ氏だ
今回もお相手は前回に引き続き、NVIDIA Vice President&Technical Marketingを務めるTトニー・タマシ氏だ演算精度は「FP24精度で十分?」「FP32精度が必要?」
2003年世代に引き続き2004年世代のGPUでも、プログラマブルピクセルシェーダの演算精度がATIとNVIDIAでは異なっている。ATIのRADEON X800シリーズは先代RADEON 9800シリーズ同様24ビット浮動小数点実数(FP)精度で、対するGeForce 6800シリーズは先代これもGeForce FXシリーズ同様の32ビットFP精度を採用している。
ATIは、「今のリアルタイム3Dグラフィックスでは、ピクセル陰影処理の演算精度に24ビットで必要十分」という見解を示している。この演算精度にまつわる、両社の考えの相違点についての意見を聞いてみた。
タマシ氏 前回同様のGPUデザイントレードオフにまつわる問題です。内部レジスタをFP24でデザインできれば内部レジスタ容量を小規模に出来るし、積和算器を初めとしたいろいろな演算器も小規模に出来ます。ただ、確実にいえることは、FP24精度はFP32精度よりも精度的に劣ると言うことです。
RADEON X800においてもFP24精度を採択したのは、もちろんベースアーキテクチャがRADEON 9800系であることも大きいと思うが、それ以外にも、シェーダ 2.0仕様に留まったことで、FP32精度への移行の必要性が少なかったとも考えられる。
シェーダ 3.0仕様では、頂点シェーダによるテクスチャへのアクセスが可能となっており、テクスチャデータとしてテーブルに記録されたベクトルデータを使って頂点を変位させる「ディスプレースメントマッピング」(D-MAP)が可能となっている(ただし、シェーダ 3.0仕様のD-MAPは、Matrox Parhelia系のそれとは異なり、頂点数の増減はないシンプルなもの)。
頂点シェーダ自身は、このベクトルデータ・テクスチャからデータが読み出せるだけで、内容を書き換えたりする能力は持たない。よって、このテクスチャの内容を変化させて、動的、かつインタラクティヴなD-MAPを行うためにはピクセルシェーダの力を借りる必要がある。つまり、シェーダ 3.0仕様では「ピクセルシェーダでテクスチャを更新して、これを頂点シェーダで利用する」といったパイプラインが構成できるのだ。
頂点シェーダの演算精度はRADEON X800もGeForce 6800もFP32精度(FP32×4=FP128精度という書き方をする場合もある)だ。一方、ピクセルシェーダの演算精度は、前述したようにFP24(ATI)とFP32(NVIDIA)の違いがある。ピクセルシェーダ→頂点シェーダという処理系が起こりうるシェーダ3.0仕様では、演算精度が異なっていてはまずい。
シェーダ 2.0仕様に留まったRADEON X800シリーズはこの問題に直面しないからこそ「リアルタイム3DグラフィックスにおいてはFP24精度で十分」と言い切れるのだろう。
 ATIのRADEON X800シリーズのために作られたリアルタイムレンダリングによる短編映画風デモ「RUBY-THE DOUBLE CROSS」 この映像クオリティを見る限りではFP24精度の不利なところは感じられないが……
ATIのRADEON X800シリーズのために作られたリアルタイムレンダリングによる短編映画風デモ「RUBY-THE DOUBLE CROSS」 この映像クオリティを見る限りではFP24精度の不利なところは感じられないが……タマシ氏 この頂点シェーダとピクセルシェーダの演算精度の相違は、Direct X 9世代GPU、それこそシェーダ2.0仕様GPUでも問題になりうるのです。
──頂点バッファレンダリング(Render-to-Vertex Buffer)テクノロジですね。FPフォーマットのフレームバッファに頂点情報に相当する内容をレンダリングし、これを頂点シェーダに戻す処理系で、セミ頂点シェーダ3.0仕様みたいな感じですですよね。OpenGLでもARB Superbuffersテクノロジ(www.ati.com/developer/gdc/SuperBuffers.pdf)の一つとして定義されていると、去年のSIGGRAPHのセッションで聞いてきました。
タマシ氏 RADEON 9700/9800系でもこの機能が使えますが、これらATIのGPUでは、ピクセルシェーダがFP24精度で生成した頂点バッファを頂点シェーダがFP32精度で処理することになりますから、上記の演算精度の違いの問題が生じることになります。
とにかく、いまのGPU世代でFP24精度の優位性を語るのは無理がある私は思います。
頂点バッファレンダリングは、メインメモリとビデオメモリの区別がないXboxでは効果的に活用されている例もあるそうだが、PCでこれを効果的に活用した例はあまり多くない。よって、RADEON系のピクセルシェーダのFP24演算精度が、それほど大きな問題を引き起こすことはめったにないとは思うのだが、一つの可能性としては確かに「その通り」である。
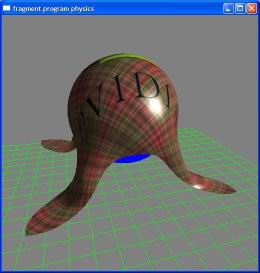 頂点バッファレンダリングは、GPUで物理シミュレーションをやるときにも有用とされる。画面は頂点バッファレンダリング技術を使って布の挙動のシミュレーションを行ったデモ。詳細はNVIDIAの開発者ページ(http://developer.nvidia.com/object/demo_cloth_simulation.html)を参照されたし
頂点バッファレンダリングは、GPUで物理シミュレーションをやるときにも有用とされる。画面は頂点バッファレンダリング技術を使って布の挙動のシミュレーションを行ったデモ。詳細はNVIDIAの開発者ページ(http://developer.nvidia.com/object/demo_cloth_simulation.html)を参照されたしネイティヴ vs.ブリッジソリューション。NVIDIAは本当に不利なのか
RADEON X800系とGeForce 6800系とでは、ある最新フィーチャーに対するスタンスが決定的に異なっている部分がある。
それはPCI-EXPRESSへの対応スタンスだ。
先行して発表されたRADEON X800系は、GPUコア内部にAGP 8Xインタフェースを内蔵したAGP 8X版だが、先日COMPUTEX TAIPEI 2004でGPUコア内部にPCI-Expressインタフェースを内蔵したPCI-Express版が発表された。
これに対し、GeForce 6800系は内部バスをAGP 16Xとし、これをPCI-Expressインタフェースへの変換ブリッジチップを組み合わせてPCI-Expressに対応する予定になっている。
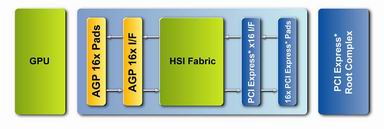 NVIDIAのGPUはPCI-Expressへの対応にはHSIブリッジチップを用いる
NVIDIAのGPUはPCI-Expressへの対応にはHSIブリッジチップを用いる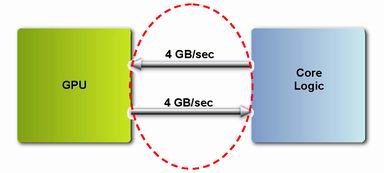 ネイティヴソリューションの場合は理論上、上り下りがそれぞれ4Gバイト/秒の帯域を持つと説明される。図中のCore Logicとはチップセットのこと
ネイティヴソリューションの場合は理論上、上り下りがそれぞれ4Gバイト/秒の帯域を持つと説明される。図中のCore Logicとはチップセットのことというわけで、2004年世代は、いわゆるPCI-Expressへの「ネイティヴ対応」(ATI) vs.ブリッジ対応」(NVIDIA)という戦いが繰り広げられるのである。
Copyright © ITmedia, Inc. All Rights Reserved.
アクセストップ10
- きょう発売の「MacBook Neo」、もうAmazonで割安に (2026年03月11日)
- セールで買った日本HPの約990gノートPC「Pavilion Aero 13-bg」が想像以上に良かったので紹介したい (2026年03月11日)
- 10万円切りMacが17年ぶりに復活! 実機を試して分かったAppleが仕掛ける「MacBook Neo」の実力 (2026年03月10日)
- 12機能を凝縮したモニタースタンド型の「Anker 675 USB-C ドッキングステーション」が27%オフの2万3990円に (2026年03月11日)
- 3万円超でも納得の完成度 VIA対応の薄型メカニカルキーボード「AirOne Pro」を試す キータッチと携帯性を妥協したくない人向け (2026年03月12日)
- 「MacBook Neo」を試して分かった10万円切りの衝撃! ただの“安いMac”ではなく絶妙な引き算で生まれた1台 (2026年03月10日)
- エンスージアスト向けCPU「Core Ultra 200S Plus」登場 Eコア増量+メモリアクセス高速化+バイナリ最適化でパフォーマンス向上 (2026年03月11日)
- M5 Max搭載「14インチMacBook Pro」がワークステーションを過去にする 80万円超の“最強”モバイル AI PCを試す (2026年03月13日)
- 新型「MacBook Air」はM5搭載で何が変わった? 同じM5の「14インチMacBook Pro」と比べて分かったこと (2026年03月10日)
- 高音質・良好な装着感・バッテリー交換式――JBLのフラッグシップ「Quantum 950 WIRELESS」は妥協なきヘッドセットか (2026年03月12日)
過去記事カレンダー
Feed Back
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。