au「声de入力」は、今までの音声認識とどこが違う?
KDDIが発表した新サービス「声de入力」(1月12日の記事参照)は、ナビの地名入力や乗換案内の駅名入力といった操作を、キーではなく音声で可能にしたものだ。
しかし携帯電話で音声認識を利用した製品やサービスはこれが初めてではない。従来の音声認識技術と声de入力はどこが違うのか、またKDDIの狙いなどについてまとめた。
キーが苦手な人には「声」で入力してほしい
「携帯電話は単なる通話の道具ではなく、個人の情報ツールになってきているが、キー入力が困難という声がある」と話すのは、au商品企画本部モバイルサービス部の幡容子氏だ。
メールやWeb検索、ナビ、アドレス帳など、携帯の機能が多様化していく中で、キーによる文字入力が必須なために、そこが利用のハードルになってしまっているケースは多い。「初心に返って、より多くの人により簡単に機能を使ってもらいたいと考えた」(幡氏)。また、ビジネスマンが“歩きながら”“待ちながら”EZナビウォークを使うシーンも想定しているという。
 au商品企画本部モバイルサービス部の幡容子氏
au商品企画本部モバイルサービス部の幡容子氏これまでの携帯電話にも、音声認識技術を利用している製品はある。例えば、電話帳に登録した電話番号や、メニューの呼び出しなどを単語で呼び出せる機能を持ったものなどだ(2002年9月10日の記事参照)。
ただ、これらのケースでは、単語を認識しているだけだ。声de入力の場合は「東京から新宿まで10分後」など、短い文章を認識できるため、その分処理しなくてはならないデータ量も増える。携帯電話の非力な処理能力で自然文認識を可能にしているのが「DSR」という技術だ。
端末とサーバで処理を分散
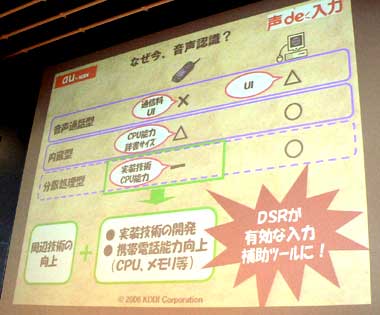
携帯電話の文字入力に音声認識技術を使う試みは古くからあり、大きく3つに分けられる。携帯の端末で処理を行う「内蔵型」、音声認識処理はサーバに行わせて、通話回線を利用して問い合わせる「音声通話型」、そして端末とサーバと処理を分散する「分散処理型」だ。
内蔵型の場合は、通信が発生しないためユーザビリティに優れるが、半面、端末の処理能力が高くないこと、また辞書のサイズを大きくできないという理由から、数十単語しか認識できないという問題があった。
音声通話型の場合、処理能力の高いサーバ側で音声認識処理を行うため、大容量の辞書を登録でき、認識率も上げやすいが、ユーザーが音声認識をしようとするたびに、音声認識用のアプリと音声回線を切り替え、通信を行わなくてはならない。何度も通信が発生し通信料・時間がかかること、何度も切り替えが必要でユーザーにとって使いにくいなど、ユーザビリティの面で問題があった。
声de入力では、端末とサーバとで処理を分担する分散型音声認識機能(DSR:Distributed Speech Recognition)を採用している。「Symbian OSやWindows MobileといったOSを載せたスマートフォン以外で、DSRを実現したのは世界初」(幡氏)。
 内蔵型、音声通話型、DSRのそれぞれの特徴
内蔵型、音声通話型、DSRのそれぞれの特徴具体的には、ユーザーが発声した内容の音声特徴をパラメータとして抽出するまでを端末側で行い、そのデータをパケット通信でサーバへ送信する。サーバ側では、送られてきたパラメータを辞書と照合して、認識結果をパケット通信で端末に送る仕組みになっている。
DSRでは、内蔵型に近いユーザビリティと、音声通話型並みの認識率を両立でき、しかも通信の回数も音声通話型に対して少なくできる。内蔵型と音声通話型の“いいとこ取り”ができる方法だが、これまで携帯電話への実装は難しかったという。「周囲の雑音の除去など、周辺技術の向上によって実現できた」(幡氏)
声de入力では、屋外など雑音がうるさいところでも、認識率を下げないよう、2種類の音声認識エンジンを持っているという。音声認識を開始する前に周囲の雑音を検出し、その雑音レベルに合わせ「雑音に強いエンジン」「高速に処理できるエンジン」を自動的に切り替える仕組みだ。
 声de入力の特徴
声de入力の特徴音声認識用のチップは追加搭載していないが、特徴パラメータの抽出、計算はBREWアプリではなく、端末上のソフトウェアで行うため、このソフトが搭載されていない現行機種では声de入力を利用することはできない。
端末が抽出する音声特徴データは、乗換案内の場合でほぼ1K〜2Kバイト、多い場合で3Kバイト程度だという。「CDMA 1Xのパケット割を適用した場合で、1回3〜4円程度」(KDDI)
他のアプリケーションへの展開は?
声de入力のベースとなっているのは、KDDI研究所が研究開発した音声特徴情報抽出ソフトウェア・音声認識エンジンだ。同研究所の音声認識技術研究の歴史は古く、「『ア』とか『イ』とかの認識から始まって、30年くらいはやっている」(KDDI研究所音声処理グループリーダーの河井恒氏)
KDDIが自然文の音声認識を利用したサービスを提供するのは、実はこれが初めてではない。沖電気と共同開発した「ITS音声ポータルサービス」(2001年7月2日の記事参照)や、「ezバーチャルトーク」というサービスを提供していたこともある(2001年8月23日の記事参照)。
今回のサービスで、声de入力を乗換検索や目的地検索と組み合わせている大きな理由は、必要な単語を地名や時間、住所などに絞りこめるため、“ユーザーが発声する場合にどのような言葉が必要で、どのような結果を返す必要があるか”を想定しやすく、認識率を上げやすいためだ。
音声認識技術を利用したアプリを作り、認識率を上げるには、想定される言葉を的確に集めたデータベースサーバを構築しなくてはならない。サーバには、全国の駅名のほか、EZナビウォークで随時利用されているキーワードのうち、上位1万件の単語が登録されている。認識が失敗した場合のデータを蓄積・学習する機能は備えていない。「現在の(EZナビウォークの)利用状況から見て、1万件で足りるという認識。2カ月に1回くらいの更新頻度になるのではないか。今後1万件(のキーワード)を入れ替えていってもいいし、増やすことも可能。状況を見て対応する」(KDDI)
EZナビウォーク以外のアプリケーションへの展開も想定している。「『今から音声認識開始』→『認識開始』→『音声認識終了』という部分のAPIは、BREWアプリから利用できるものになっている。ただ、APIを公開するかどうかは決まっていない」(KDDI)
関連記事
 地名や乗換を声で入力・検索「声de入力」の実力は?
地名や乗換を声で入力・検索「声de入力」の実力は?
「東京から新宿まで10分後」など自然な文章を発声すれば、EZナビウォークを声で操作できるサービス「声de入力」。発表会会場で気になる実力をチェックした。- au携帯で「声で乗換検索」が可能に〜分散型音声認識機能「声de入力」
au携帯向けに、音声認識機能を利用し声で入力できるサービスが提供される。発声するだけで目的地検索や乗換案内などが可能。  KDDIの三つ子ケータイはどこが違う?
KDDIの三つ子ケータイはどこが違う?
KDDIは、CDMA 1X対応の3機種を発表した。いずれも三洋電気製の「A5518SA」「Sweets pure」「A5520SA」の3機種。共通のプラットフォームを用いる3機種の違いはどこだろうか。- バーチャルな相手と会話できる「ezバーチャルトーク」登場
携帯電話片手に話している相手は,ヒトではなくなる? 声から「喜・怒・哀」の感情まで判別して,会話の相手をしてくれたり,ゲームを楽しめるサービスが,auとツーカーの携帯電話に登場する。 - 交通情報は音声にお任せ──KDDIと沖電気,携帯で音声認識
KDDI研究所と沖電気は,騒音の大きい環境でも高認識率を持つ携帯電話向けの音声認識システムを発表した。歩行者向けITSの実現に向けて,音声認識による情報サービスを実用化していく。
Copyright © ITmedia, Inc. All Rights Reserved.
アクセストップ10
- 「iPhoneの調子が悪いです」の文言、なぜアイホンのFAQに? 実はAppleと深く関係 (2026年02月08日)
- 総務省有識者会議が「手のひら返し」な我が国への示唆――日本を国際標準から遅れさせたのは自らの愚策のせい (2026年02月08日)
- 「東京アプリ」で1.1万円分をゲット、お得な交換先はどこ? dポイント10%増量+楽天ペイ抽選が狙い目か (2026年02月05日)
- KDDI、楽天モバイルとの「ローミング重複エリア」を順次終了 松田社長が言及 (2026年02月06日)
- 楽天モバイル、1000万回線突破も残る「通信品質」の課題 5G SAの早期導入とKDDIローミング再延長が焦点に (2026年02月07日)
- 東京アプリ、PayPayがポイント交換先に追加される可能性は? 広報に確認した (2026年02月05日)
- Googleが台湾のPixel開発拠点を公開 「10 Pro Fold」ヒンジ開発の裏側、“7年サポート”を支える耐久テスト (2026年02月09日)
- 東京アプリ、PayPayとWAON POINTをポイント交換先に追加 交換時期は「決まり次第案内」 (2026年02月09日)
- 「小型iPhone SEを復活させて」──手放せない理由SNSで話題 どこが“ちょうどいい”と評価されるのか (2025年11月29日)
- 【ニトリ】1990円の「スマホに付けるカードケース」 マグネット対応でスタンドとしても使える (2026年02月07日)
過去記事カレンダー
Feed Back
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。